Zadania do wykładu o typach danych (listy, tablice, hasze)
Uniwersytet Gdański - Instytut Matematyki - Zakład Informatyki - Strona domowaPerl: programowanie - Zadania do wykładu o typach danych (listy, tablice, hasze)
- Zdefiniuj trzy-elementową tablicę @tab i wpisz do niej liczby 1, 2, i 1/3.
Zadanie jest oczywiście trywialne, i nie ma tu żadnego "podstępu". Oto, co można zrobić, aby je rozwiązać:
@tab = (1,2,1/3);Element @tab to oczywiście tablica tab, która nie musiała wcześniej istnieć. Lista (1,2,3) jest przypisywana do tablicy tak, że każdy jej kolejnym element będzie odpowiednim kolejnym elementem tablicy, to znaczy, przypisanie powyższe jest równoznaczne w działaniu z napisaniem po prostu:($tab[0],$tab[1],$tab[2]) = (1,2,1/3);... które zresztą też działa. :) - Wypisz tablicę używając funkcji print na dwa sposoby:
print @tab; print "@tab";Jaka jest według ciebie różnica?Pierwsza forma bez cytowania w cudzysłowach działa tak, że wypisywane są elementy tablicy we właściwy dla siebie sposób, po kolei, jeden za drugim. W przypadku cytowania za pomocą podwójnych cudzysłowów (drugi sposób), pojawia się coś jeszcze: elementy tablicy są łączone w napis i oddzielane spacją. Napis ten następnie pojawia się na wyjściu. Należy pamiętać, że cytowanie za pomocą pojedynczych cudzysłowów nie rozwinie tablicy do jej wartości, to znaczy, że napisanie '@tab' spowoduje wyprowadzenie dokładnie tego samego, czyli dosłownie @tab. - Sprawdź, co robi funkcja reverse w odniesieniu do tablicy i w odniesieniu do napisu.
reverse jest operatorem listowym. Ma to konsekwencje w postaci nieco różnego działania w kontekście listy i w kontekście skalarnym. Oto przykłady:
@tab = (1..3); print reverse @tab;Oto dwa polecenia: pierwsze tworzy tablicę 3-elementową (jeszcze inny sposób z zadania 1 w tym zestawie), drugie wykonuje operacje wypisania listy elementów tablicy @tab w odwrotnej kolejności. Odwrócenia dokonuje operator reverse, a efekt jego działania widać od razu dzięki poleceniu print. Gdyby wykonać to samo dla napisów, efekt byłby np. taki:@tab = qw(c++ php ada); print reverse @tab;Wynikiem działania takiego programu jest zbiór napisów w postaci adaphpc++. Zauważ, że tutaj korzystamy z operatora cytowania słów qw(...), dzięki któremu nie trzeba wstawiać do listy słów przecinków i cytujących apostrofów. Gdy wykonać to polecenie na pojedynczym słowie w sensie np. kodu:print reverse "foobar";... to w efekcie dostaniemy to samo słowo. Przyczyną tego jest właśnie fakt, że reverse to operator listowy, i jeden argument traktuje jak listę jednoelementową. Odwrócenie takiej listy daje dokładnie taką samą listę, co sprawia wrażenie, jakoby reverse nie zadziałał. Można wymusić kontekst skalarny i wtedy następuje odwrócenie liter w napisie:print scalar reverse "foobar";Kontekst skalarny jest także w momencie przypisania wyniku do zmiennej skalarnej, więc np. poniższy kod także zadziała:$a = reverse "foobar"; print $a; - Znajdź sposób aby zamienić miejscami dwie zmienne nie używając dodatkowej
zmiennej. Sprawdź, czy ten sposób nadaje się do zamiany miejscami wartości
trzech lub czterech zmiennych.
Wystarczyło zrobić program, który na przykład wygląda tak:
$a = 1; $b = 2; ($a,$b) = ($b,$a); print "a=$a, b=$b\n";Taka sama jest procedura dla trzech zmiennych, gdyby trzeba było zamienić ich zawartość (np. w sortowaniu trzech liczb):($a,$b,$c) = (1,2,3); ($a,$b,$c) = ($b,$c,$a); print "a=$a, b=$b, c=$c\n";Takie postępowanie można prowadzić dalej, a perl automatycznie będzie odpowiednio zamieniał wartości w zmiennych, bez obaw o przedwczesne nadpisanie niektórych z nich. Sposób ten jest w ogólnym przypadku niewygodny, i w ciągu ponad dziesięciu lat praktyki w programowaniu w różnych językach nie zdarzyło mi się, abym miał potrzebę zamienić miejscami wartości w czterech zmiennych naraz... :) Więc to raczej akademicki przykład :)
Update 20070320: jeden ze studentów (W.G.) podesłał mi taki kawałek kodu (wykorzystujący operację xor):perl -le '$a=1; $b=2; $a^=$b^=$a^=$b; print "$a $b"'Update 20070615: jeden z moich studentów (P.B.) przysłał mi takie rozwiązanie (wykorzystujące operację dodawania/odejmowania):perl -le '$a=1; $b=2; $a+=$b; $b=$a-$b; $a-=$b; print "$a $b";'Dziękuję! :) - Jeżeli zadanie powyższe wydało ci się dość proste, pora na odrobinę myślenia: zaproponuj i przetestuj sposób przestawienia całej tablicy liczb, tak, aby liczby znajdujące się na końcu tablicy ustawione zostały na jej początku i vice versa. Przykład: tablica @T równa (1,2,3,4,5,6,7,8,9) ma po operacji być równa (9,8,7,6,5,4,3,2,1). W ogólności - niezależnie od liczby swoich elementów.
Nie jest to żadna filozofia - wystarczy użyć poznanego wcześniej operatora reverse. Służy on właśnie do odwracania list dowolnej długości.
- Sprawdź co się stanie, gdy spróbujesz wykonać kod:
$tablica[4] = 1; print "@tablica\n";Co można powiedzieć o elementach tablicy? Sprawdź działanie tego programu dla przypadku, gdy perla uruchamiasz z opcją -w.W tym przypadku wiele zależy od tego, czy tablica @tablica istniała wcześniej w programie. Gdyby istniała, zapis taki mógłby zmienić wartość piątego elementu lub gdyby tablica miała mniej niż pięć elementów - nastąpiłoby dodanie brakującej liczby elementów mających wartość undef i następnie ustawienie wartości piątego licząc od początku tablicy na 1. Zatem w przypadku, gdy tablicy nie było, będzie ona zawierała pięć elementów, i wszystkie cztery pierwsze uzyskają wartość undef, a ostatni z nich będzie miał wartość 1. - Utwórz tablicę 1000-elementową liczb od 1 do 1000. Następnie usuwaj z tej tablicy wszystkie liczby parzyste, potem podzielne przez 3, podzielne przez 4, itp. Jest to tzw. sito Erastotenesa (nie mylić sita z sitwą!). Sprawdź, ile zostało liczb w twojej tablicy.
Jest to w zasadzie proste zadanie algorytmiczne, i łatwo znaleźć na sieci gotowe algorytmy rozwiązujące z wieloma możliwymi wariacjami postawione wyżej zadanie. Jest to niezwykle wdzięczny temat także dla łowców perlowych 'onelinerów', gdyż istnieją bardzo krótkie jednolinijkowce, które potrafią zachwycić. Najpierw jednak odrobina prozy, czyli rozwiązania typowe dla przeciętnego studenta :) Proszę potraktować to jako komplement! :)
Typowe rozwiązanie polega na tym, aby stworzyć tablicę 1000 liczb, a następnie wykreślić z niej kolejno liczby podzielne przez coraz większe podzielniki. Tak postępując, w tablicy pozostaną tylko liczby pierwsze. Realizacja może być oparta dosłownie o test podzielności liczby (za pomocą operacji modulo) oraz podwójną pętlę, oto jedna z możliwych implementacji:use strict; my $ZAKRES = 1000; # zakres liczb jaki dopuszczamy my @LICZBY = 2 .. $ZAKRES; # tablica liczb for( my $x=0; $x<scalar @LICZBY; $x++ ){ # zasuwamy z indeksami liczb ($x = indeks) for( my $i=2; $i<= sqrt $LICZBY[$x]; $i++){ # zasuwamy po liczbach ($i = liczba) if( ! ( $LICZBY[$x] % $i ) ){ # sprawdzamy podzielność liczby pod każdym $x $LICZBY[$x] = 0; # i jeżeli dzieli się, to zerujemy ją } } } print "@LICZBY"; # a potem piszemy wszystko co zostałoTen kod nie jest nadzwyczajny, ponieważ wynik zawiera zera, których jednakże łatwo nie napisać, wystarczy instrukcję:print "@LICZBY"zastąpić bardziej złożonym poleceniem, które produkuje nieco "czystszy" wynik:print join " ",grep {$_>0} @LICZBY;Wiadomo oczywiście, że liczby, którymi dzielimy wystarczy brać co najwyżej do pierwiastka kwadratowego z testowanej liczby. Poza tym zerowane elementy można z tablicy usuwać, aby w kolejnych iteracjach skrócić wewnętrzną pętlę (pierwszy krok skraca ją o połowę, usuwając liczby parzyste!). Zamiast samych pętli można zastosować map, które jest nieco szybsze. Przedstawiony poniżej program może być oczywiście krótszy, ale ma taką wadę, że przetwarza niepotrzebnie bardzo wiele danych... Dlatego jest wolniejszy :) Niemniej, wygląda on dość niewinnie, o tak:perl -wle '@T=1..($N=1000);print join " ",grep{$_>0}(map{$i=$_;map{(!($_%$i)&&$_!=$i)?0:$_}@T}2..$#T)[0..$N-1]'Jego rozszyfrowanie jest banalne więc chyba nie będę tego tłumaczył. W razie czego, napisz maila, gdybyś miał pytania. Ostatnim przykładem rozwiązania tego zadania jest przepiękny oneliner niejakiej Abigail, powstały prawdopodobnie w 2000 roku, gdy Randal Schwartz upowszechnił jednolinijkowce. Zanim go zacytuję, powiem dla ułatwienia, że program ten sprawdza czy liczba jest pierwsza, wykorzystując symetrię oraz wyrażenia regularne. Bardzo zręczny kod! Zmodyfikowałem oryginalną wersję, aby liczyła tylko liczby do zadanego maksimum. Oto on:perl -wle '(1 x $_) !~ /^(11+)\1+$/ && print while ++ $_ < 1000' - Sprawdź, czy algorytm sortujący perla jest wrażliwy na kolejność danych wejściowych. Wygeneruj tablicę N liczb całkowitych losowych (wykorzystaj funkcję rand). Wszystkie liczby umieść w tablicy @LICZBY i wykonaj ich sortowanie (operatorem sort). Zmierz czas wykonania programu (np. poleceniem time). Liczbę N należy dobrać tak, aby sortowanie trwało kilka sekund. Sprawdź następnie jak zmieni się czas sortowania gdy spróbujesz posortować dane posortowane, ustawione w odwrotnej kolejności, itp. Porównaj wyniki z zewnętrznym poleceniem sort, które jest zainstalowane w systemie.
Algorytm sortujący perla, tak samo jak i ten wbudowany w polecenie systemowe sort, nie są wrażliwe na kolejność danych w serii, branych do sortowania. Dowodem na to są czasy sortowania miliona losowych liczb (tekstowo), które przeprowadzić można np. w taki sposób:
- Tworzymy plik z losowymi liczbami.
- Sortujemy ten plik dowolnym sposobem tak, aby otrzymać uporządkowanie roznące (A-Z) oraz malejące (Z-A). Dwa otrzymane w taki sposób pliki wykorzystamy w pomiarach.
- Sortujemy poleceniem systemowym sort każdy z plików, w kolejności rosnącej i malejącej po trzy razy, a wynik pomiarów czasu uśredniamy.
- Takie samo sortowanie wykonujemy korzystając z perla i wyniki pomiarów czasu porównujemy z otrzymanymi w systemowym sort.
Zamiana na liczbę kosztuje: czas sortowania jest dłuższy. Hm. Czy nie wydaje Ci się, że perl działa szybciej w obu przypadkach od polecenia systemowego, które przecież napisano w C i skompilowano (to taka malutka indoktrynacja)? Sprawdź najlepiej sam, na swoim własnym systemie.Wyniki dla porównań tekstowych (czasy w [s]) Wyniki dla porównań liczbowych (czasy w [s]) Pobierz Pomiar sort A-Z sort Z-A perl A-Z perl Z-A Plik A-Z 5.565.421.911.90Plik Z-A 4.945.151.861.90Pomiar sort A-Z sort Z-A perl A-Z perl Z-A Plik A-Z 5.219.082.862.63Plik Z-A 5.417.382.492.47
ok. 36MB! - Napisz program, który korzystając z tablic wielowymiarowych dodaje macierze. Każdą macierz przed dodaniem należy wczytać klasycznie pytając o kolejne elementy; program może podawać ich współrzędne dla orientacji. Wynikowa suma macierzy powinna zostać ładnie (względnie) wypisana w celu umożliwienia jej oględzin.
Odpowiedź jest przedstawiona w formie programu, który można pobrać stąd (jest w postaci pliku tekstowego). Przykładowe wykonanie programu pokazuje poniższy rysunek:Postać wynikowa dla przypadku macierzy 10x10 z danymi wczytywanymi z pliku:
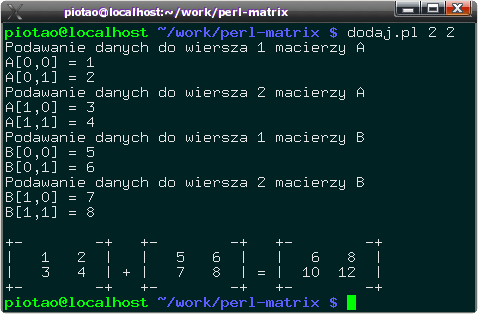 Wynik działania programu do dodawania macierzy wywołanego z rozmiarem 2x2. Program pyta o dane interaktywnie, ale gdyby uruchomić go przekierowując do niego dane z jakiegoś pliku, żadne pytania niepojawiłyby się. Odpowiada za to test if -t *STDIN, które sprawdza, czy wejście do programu jest powiązane z terminalem, na który można pisać.
Wynik działania programu do dodawania macierzy wywołanego z rozmiarem 2x2. Program pyta o dane interaktywnie, ale gdyby uruchomić go przekierowując do niego dane z jakiegoś pliku, żadne pytania niepojawiłyby się. Odpowiada za to test if -t *STDIN, które sprawdza, czy wejście do programu jest powiązane z terminalem, na który można pisać.
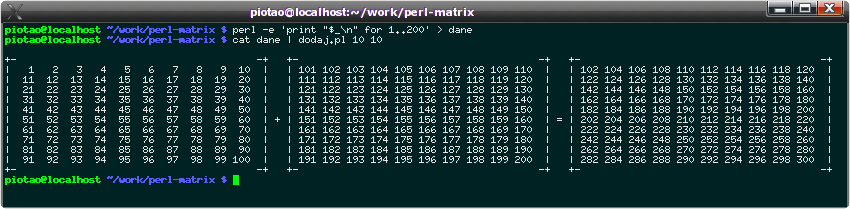 Program sprawdza, czy można pisać na terminal, i gdy nie można (bo np. nastąpiło przekierowanie) - nie pisze niczego poza wynikami.
Program sprawdza, czy można pisać na terminal, i gdy nie można (bo np. nastąpiło przekierowanie) - nie pisze niczego poza wynikami.
- Jak w perlu połączyć dwie tablice nie używając push, unshift ani splice? Napisz prosty program demonstracyjny, który wykonuje to zadanie. Rozważ przypadki dołączenia tablicy na początku, na końcu lub gdzieś w środku innej tablicy. Napisz przykładowe programy.
To oczywiście bardzo proste. Wystarczy wykorzystać przypisania list do list. Łączenie dwóch tablic polega wtedy na umieszczeniu ich w liście, gdzie zostają automatycznie spłaszczone i połączone w jedną listę. A taką listę można bez trudu przypisać do jakiejś nowej tablicy, uzyskując wtedy tablice połączone... i tak samo w pozostałych przypadkach:
@A = 1..10; @B = 100..200; # wstawienie tablicy @B przed tablicę @A: @C = (@B,@A); # wstawienie tablicy @B za tablicę @A: @C = (@A,@B); # wstawienie tablicy @B pomiędzy element 4 i 5 tablicy @A: @C = (@A[0..3], @B, @A[4..$#A]); - Napisz program do mnożenia niewielkich macierzy, powiedzmy, całkowicie mieszczących się w pamięci.
Mnożenie macierzy wykonywane jest przez nieco dłuższy program (ze względu na to, że nie chciałem w nim używać funkcji upraszczających kod), i dlatego można źródła znaleźć w wersji plików HTML w pliku pomnoz.pl. Program ten pobiera jako argument nazwę pliku i wczytuje z tego pliku dane. Powinny w nim znajdować się dwie macierze zapisane w naturalnej postaci kolumnowo-wierszowej, oddzielone od siebie jedną pustą linią, np:
2 3 4 5 4 3 3 1 5 3 2 4 5 5 6 1 0 2Program wyświetla wynik mnożenia w sposób podobny do mnożenia pisemnego. I jak to często bywa, w programie tym ukrywa się przynajmniej jeden błąd! :) Dla chcąch spróbować swoich sił na większych macierzach, zamieszczam także generatorek plików wejściowych: generuj.pl, który tworzy pliki z macierzami o podanych wymiarach, np. generuj.pl 3 5 stworzy np. taki plik:7 9 4 0 4 2 9 6 0 9 2 6 2 9 7 0 5 5 9 9 7 0 1 1 7 8 2 0 2 3Poszczególne liczby są oczywiście losowane, więc będziesz miał wyjątkowe szczęście, jeżeli trafisz na dokładnie taką kombinację cyfr. :) W razie potrzeby, zamieszczam także wersje tekstowe tych dwóch programów (może łatwiej będzie pobrać niż ze źródła HTML): generuj.pl oraz pomnoz.pl - Wygeneruj tablicę (o rozmiarze N>100) liczb rzeczywistych większych od 1.00 i wykonaj jej normalizację do 1.00.
W tym zadaniu chodzi o napisanie programu, który wygeneruje więcej niż 100 liczb (np. 200), taki, że będą losowe, rzeczywiste i większe od 1.0, a następnie wykona wyszukanie wartości maksymalnej i podzieli tą wartością wszystkie liczby. Taki proces nazywa się normalizacją. Program, który wykonuje to zadanie, można pobrać z pliku normalizacja.pl lub normalizacja.txt
- * Napisz program, który generuje histogram z serii otrzymanych danych. Histogram powinien być generowany z konfigurowalną precyzją i z możliwością zmiany formatu wyświetlania liczb.
Rozwiązanie jest zawarte w pliku histogram.pl dostępnym także w wersji tekstowej. Przykład działania programu znajduje się na rysunku poniżej. Generowany jest najpierw zbiór 1000 losowych liczb z zakresu od 0 do 99, w jednej kolumnie. Następnie tworzony jest histogram, który jak widać pokazuje ilości liczb w każdym z przedziałów. Dla dłuższych serii liczb losowych ich ilości powinny być coraz bardziej podobne, o ile generator liczb losowych jest naprawdę losowy.
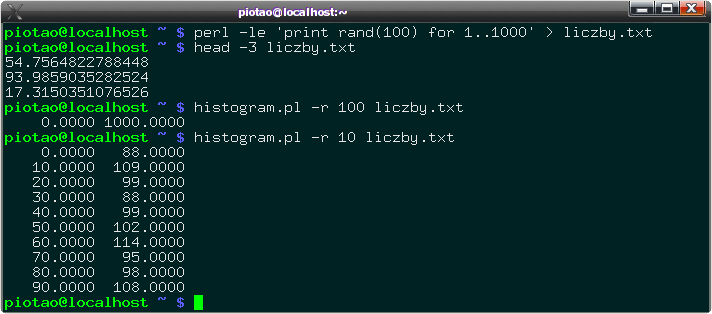 Wynik zastosowania programu liczącego histogram do serii danych losowych. Pierwsze uruchomienie z zakresem 1000 (-r 1000) wychwyciło w jeden przedział całą serię danych, co jest prawidłowe. Skala 10 ukazuje ilość liczb z serii danych znajdującą się w każdym przedziale.
Wynik zastosowania programu liczącego histogram do serii danych losowych. Pierwsze uruchomienie z zakresem 1000 (-r 1000) wychwyciło w jeden przedział całą serię danych, co jest prawidłowe. Skala 10 ukazuje ilość liczb z serii danych znajdującą się w każdym przedziale.
Zadania dodatkowe (listy i tablice)
- Sprawdź kilka przypadków związanych z wzajemnymi interakcjami tablicy, listy i wartości skalarnych:
print +(1,2,3,4)[2]; @a = (1,2,3,); @a = (((((1,2,3))))); @a = (1,2,3, (), (), ( (), ), ); $a = (1,2,3); @a = () = (1,2,3); $a = () = (1,2,3); @a = $a; # gdy wartość zmiennej $a wynosi np. 2 @a = $a; # gdy zmienna $a nie została zdefiniowana $a = @a; $a = scalar @a; $a = scalar (@a); $a = scalar (); $a = scalar +(); $a = scalar (()); (@a)[2]; (1,2,3)[1]; (1)[2,3]Korzystając z mądrości zawartych w perldoc zrozum te przykłady. Są to absolutne podstawy perla... :)print +(1,2,3,4)[2];Lista może być indeksowana, podobnie jak tablica. Indeksy zaczynają się standardowo od zera, dodatkowo dozwolona jest odwrotna numeracja - ostatni element ma indeks równy -1, przedostatni -2, itp. Poniższy przykład powoduje wypisanie trzeciego elementu równego 3.
@a = (1,2,3,);Lista może być zakończona przecinkiem, który w takim przypadku nie powoduje błędu składni. Element za przecinkiem jest traktowany jak pusta lista, czyli element o zerowej długości. Przecinki można powtarzać i nie powoduje to błędów: (1,,,2,,3,,,,,4,,). Często na końcu listy zostawia się przecinek za ostatnim elementem. W operatorze cytowania qw{} nie należy stosować przecinków - elementy listy są bowiem oddzielane od siebie białymi znakami.
@a = (((((1,2,3)))));Lista wewnątrz listy jest "spłaszczana" do listy nadrzędnej. Powoduje to, że lista list, staje się "płaską" listą. Zapis z wieloma nawiasami jest w tym przypadku równoważny zapisowi bez wewnętrznych nawiasów: (1,2,3). Mimo to w pewnych przypadkach mogą mieć znaczenie grupujące, jeżeli wewnątrz listy znajduje się jakaś funkcja pobierająca argumenty w postaci listy.
@a = (1,2,3, (), (), ( (), ), );Puste nawiasy są równoważne z pustą listą, która dodatkowo jest łączona w tym przypadku z listą otaczającą, powodując jakby konwersję do postaci (1,2,3,,(,),) a potem do (1,2,3,,,,) i w końcu do (1,2,3).
$a = (1,2,3);Lista może być przypisana do skalara, jednakże wynikiem tego przypisania jest tylko ostatni element listy. Lista nie może istnieć w kontekście skalarnym i nie odbywa się w tym przypadku konwersja do liczby elementów. Zostaje zwrócony ostatni element, a wszystkie elementy są obliczane (jeżeli są wyrażeniami) w kierunku od lewej do prawej. Zatem wynikiem przypisania jest ostatnio obliczona wartość, ze względu na działanie operatora przecinka jest to wartość z prawej strony listy.
@a = () = (1,2,3);Przypisanie listy do pustej listy, umieszczone dodatkowo w kontekscie listy przez przypisanie wyniku do tablicy @a. Prawidłowa kolejność działań w tym wyrażeniu wygląda tak: @a = ( () = (1,2,3) );. Wynikiem przypisania jest lista pusta (jest to wartość wyrażenia zwracana przez operator =), i ta wartość jest przypisywana w drugim kroku obliczania wyrażenia do @a: @a = ();. Zamiana miejscami nawiasów prowadząca do wyrażenia (@a=()) = (1,2,3); także daje listę pustą, ponieważ najpierw wykonają się nawiasy z pierwszym przypisaniem, w wyniku czego otrzymana zostanie lista pusta, a potem do tej listy zostanie przypisana lista (1,2,3). Ponieważ jest to przypisanie listy do listy pustej, i dodatkowo wynik ten nie jest nigdzie zapamiętany, zmienna tablicowa @a pozostanie pusta, jak po pierwszym przypisaniu.
$a = () = (1,2,3);Przypisanie listy do pustej listy w kontekście skalarnym. Wyrażenie to działa wg. kolejności przedstawionej przez nawiasy: $a = ( ()=(1,2,3) );. Przypisanie listy do listy pustej w kontekście skalarnym ma wartość równą długości przypisywanej listy, dlatego, że do pustej listy zostaną przypisane wszystkie elementy listy przypisywanej (1,2,3). Przypisanie to dotyczy trzech elementów, i zwraca wartość wynosi 3. Gdyby zmienić nawiasami kolejność obliczania: ($a=()) = (1,2,3); to wynikiem zachowanym w zmiennej $a byłoby 1, dlatego, że najpierw nastąpi przypisanie pustej listy do skalara (co nada skalarowi wartość undef), a następnie wykona się przypisanie ($a) = (1,2,3); w kontekście listy, co spowoduje wpisanie do zmiennej $a wartości takiej, jaką miał pierwszy element listy. Pamiętaj, że wartość operatora przypisania listy do skalara może być inna niż wartość listy przypisanej do skalara (mówiąc trochę bardziej potocznie i mnie prawidłowo). To znaczy, co innego jest wartością dla operacji skalar = (lista = lista), a co innego dla operacji $ = lista)
@a = $a; # gdy wartość zmiennej $a wynosi np. 2W przykładzie tym następuje przypisanie zmiennej skalarnej, do zmiennej tablicowej. Mimo, że obie zmienne mają nazwę a, to nie ma konfliktu nazw ze względu na różne typy zmiennych (perl na to pozwala!). Przypisanie to następuje w kontekście listy, ponieważ po lewej stronie operatora przypisania stoi zmienna tablicowa. W wyniku przypisania otrzymujemy tablicę, która w pierwszym swoim elemencie zawiera wartość zmiennej $a, np. 2, gdyby wcześniej w $a umieszczono wartość 2.
@a = $a; # gdy zmienna $a nie została zdefiniowanaPrzypisanie skalara do tablicy także odbywające się w kontekście listy, z tym, że zmienna $a nie była zdefiniowana. W takiej sytuacji będzie także zmienna $a w momencie swojego pierwszego użycia. Ponieważ zmiennej nie było wcześniej, zostaje ona powołana do istnienia z wartością undef, i taka też wartość wpisuje się do pierwszego elementu tablicy. Po wykonaniu operacji przypisania tablica będzie zawierała tylko jeden element. Jeżeli były w niej wcześniej jakieś elementy, zostaną usunięte.
$a = @a;Przypisanie tablicy @a do zmiennej skalarnej $a. Wynikiem tego przypisania jest liczba elementów w tablicy, ponieważ przypisanie następuje w kontekście skalarnym (bo przypisujemy do skalara), a w takim kontekście tablica zwraca liczbę swoich elementów (uwaga - lista zwraca swój ostatni element!).
$a = scalar @a;Przypisanie tablicy @a na której wymuszono kontekst skalarny za pomocą operatora scalar do skalara $a. Wynikiem jest oczywiście liczba elementów w tablicy @a. Jeżeli tablica nie miała żadnego elementu to przypisywaną wartością jest 0.
$a = scalar (@a);Przypisanie tablicy @a konwertowanej na skalar przez funkcję scalar do skalara $a. Wynikiem przypisania jest liczba elementów tablicy (dokładnie tak samo, jakbyśmy opuścili nawiasy).
$a = scalar ();Przypisanie, które generuje błąd składni ze względu na wywołanie funkcji scalar bez wymaganej liczby argumentów.
$a = scalar +();Przypisanie do skalara $a wartości skalarnej wymuszonej na pustej liscie przez operator scalar. W tym wyrażeniu, scalar nie jest traktowany jak funkcja, dlatego, że nie stoi zaraz po słowie scalar lewostronny nawias okrągły. Stoi tam znak + jednoargumentowny, który jest w tym kontekście ignorowany, ale zabezpiecza przed traktowaniem scalar jako funkcji, w którym to przypadku w nawiasach wymagany byłby argument. Nawiasy są zatem traktowane jako lista, w dodatku pusta.
$a = scalar (());Przypisanie do skalara $a wartości otrzymanej z funkcji scalar() której przekazano pustą listę jako argument. Ten zapis jest syntaktycznie poprawny i działa, ponieważ pierwsza para nawiasów w scalar(()) dotyczy funkcji, dopiero druga, wewnętrzna para nawiasów jest listą, w dodatku pustą. Działają też przypadki gdzie podano wiele list w listach, np. scalar(((())));, itp.
(@a)[2];Trzeci element tablicy @a skonwertowanej do listy i zaindeksowany w liście. Zamiast pisać w ten sposób, prościej napisać po prostu $a[2].
(1,2,3)[1];Drugi element z listy dostępny dzięki indeksowaniu list.
(1)[2,3]Lista pusta w kontekście listowym lub wartość undef w kontekście skalarnym. Mamy tu zwykły przypadek indeksowania listy (jednoelementowej) poza zakresem obejmowanym przez listę. Podobnie byłoby gdybyśmy np. napisali (1..10)[188], itp. Ponieważ indeksowane wartości nie istnieją, nie są zwracane z listy, bo ich tam nie ma. Dlatego wynikiem jest lista pusta. Natomiast w kontekście skalarnym wartość undef pojawia się dlatego, że taka jest wartość zwracana przez pustą listę w kontekście skalarnym.
- Napisz mały program mieszający elementy tablicy poprzez przestawienia elementów.
Jest wiele sposobów na rozwiązanie tego zadania, np. taki:
perl -le @a=1..10;print "@a";push @b,splice @a,rand @a,1 while @a;print "@b";Kod ten działa tak, że najpierw tworzona jest tablica @a do której wpisywana jest lista liczb od 1 do 10. Następnie tablica ta jest wypisywana po umieszczeniu jej w interpolowanym napisie, gdzie pomiędzy poszczególne elementy perl doda spację. Potem wykonywana jest instrukcja push do tablicy @b, elementu wyciętego przez splice z tablicy @a, a pozycji wylosowanej przez rand @a, i tylko 1-ego elementu w każdej iteracji pętli while @a, która wykonuje się tak długo, jak długo istnieją jakieś elementy w tablicy @a. Warto zwrócić tu uwagę na konteksty, dzięki którym takie rozwiązanie działa. Po pierwsze, polecenie push wymaga podania w pierwszym argumencie jawnie tablicy, i dlatego ustawiamy tam tablicę, np. jakieś @b. Następne elementy mogą być opcjonalne dla push i może być ich dowolnie wiele. Tutaj następnym elementem jest wynik działania operatora splice, który sam wymaga dostarczenia kilku elementów. Są one pobierane z następującej potem listy @a, rand @a, 1 (gdyż splice jako operator listowy pobierze tyle elementów ile może, aby "wysycić" swoje argumenty). Dlatego wyrażenie 1 while @a nie zostanie wykonane jako takie, ponieważ operator splice zdąży "zabrać" jedynkę jako swój ostatni argument. Poza tym, wyrażenie while @a użyte jest tutaj w notacji dopełnieniowej, to znaczy odwróconej, zamiast while(@a){...}, co pozwala na uproszczenie zapisu. W tym wyrażeniu tablica umieszczona jest w kontekście boolowskim, czyli logicznym, a jest to odmiana kontekstu skalarnego, zatem tablica zwraca liczbę swoich elementów (podobnie jakby było napisane while (scalar(@a) > 0). Tablica @a jest w każdym wykonaniu pętli while skracana o jeden element przez splice, dzięki czemu liczba elementów w tej tablicy spada i pętla może się kiedyś zakończyć. Bez operatora splice ten program wykonywałby się w nieskończoność. Warto także pamiętać o tym, że wyrażenie rand @a,1 nie jest traktowane przez perla jak rand(@a,1), gdyż operator rand jest operatorem skalarnym, który wymaga tylko jednego argumentu skalarnego, i wymusza taki kontekst na swoim argumencie. Dlatego tablica @a zamieniona zostaje na liczbę elementów, które zawiera, i dlatego losowanie w ten sposób jest bezpieczne, ponieważ dostaniemy wartość z zakresu od 0 (włącznie) do liczby elementów pomniejszonej o 1 (standardowe działanie rand). Taki prosty program, a ile w nim ciekawych elementów... :) I nie są to wszystkie, które można w nim znaleźć. :) Na końcu wypisywana jest tablica @b, aby można było zobaczyć przemieszane elementy. - Napisz program obliczający wyniki studentów. Podaj wynik każdego z nich jako procent uzyskanych wszystkich punktów. Wykorzystaj tablice z wynikami kolokwiów. Przyjmij, że tablice danych, które masz w programie zawierają dane zbudowane według zasady:
@dane = ( [ 'Zyndarm Izotop', 2, 4, 1, ... ], [ 'Eustachy Motyka', 3, 0, 4, ... ], ... );Aby wykonać to zadanie, napisz kompletny program, z dokumentacją POD, i załącz go w mailu do prowadzącego zajęcia. Zadbaj o prawidłową reprezentację danych, i prawidłowe wyświetlanie wyników. Zadbaj też o wcięcia kodu wykonane za pomocą spacji lub tabulacji oraz sensowność komentarzy, jeżeli jakieś (poza PODem) umieścisz w kodzie. Za dobrze wykonany program możesz otrzymać dodatkowy jeden punkt, pod warunkiem, że będzie spełniał wszystkie warunki postawione w zadaniu. Termin nadsyłania programów ustalony będzie przez prowadzącego.Prosty program wykonujący to zadanie jest przygotowany do pobrania z serwera delta. Odpowiednie zasoby poniżej:
studenci.pl
studenci.txt
studenci.pod - Napisz program obliczający średnią uogólnioną stopnia 0, 1 i 2 dla dowolnego ciągu liczb. Zadbaj o dokumentację i postać programu; podobnie jak w poprzednim zadaniu, możesz wysłać go do prowadzącego, a jeżeli program będzie bez zarzutu, otrzymasz jeden dodatkowy punkt. W razie gdyby nie było wiadomo, co to jest średnia uogólniona, sprawdź tutaj.
- Wymyśl i zaprogramuj swoje własne zadanie dotyczące zastosowania tablic. Wyślij je do prowadzącego: jeżeli będzie wystarczająco ciekawe, pojawi się w rozwiązaniach zadań ze stosownym komentarzem.
Niestety, nikt niczego ciekawego nie podesłał, więc odpowiedzi na to zadanie nie będzie.
Zadania dodatkowe (hasze)
Oto grupa zadań ćwiczeniowych z tablic asocjacyjnych. Spróbuj napisać wszystkie jak najlepiej.
- Utwórz w programie tablicę 1000 elementową liczb od 1 do 1000, a następnie przypisz ją do hasza. Spróbuj ocenić, która z tych struktur jest większa w sensie zajętości pamięci. Jeżeli nie masz żadnego innego pomysłu, wykorzystaj moduł Storable, opisany w sekcji Wykłady.
Programów, które realizują to zadanie można napisać wiele różnych. Ograniczyłem się do prostego jednolinijkowca, którym zapisuję na dysk dwa pliki - w pierwszym jest reprezentacja tablicy, w drugim reprezentacja hasza. Jak widać, i jak można było się spodziewać, hasz zajmuje odrobinę więcej pamięci, co widać po objętości tych plików. Oto program:
perl -le 'use Storable;@a=1..1000;%a=@a;store \@a,"dane1";store \%a,"dane2";'A tutaj efekt jego działania:Okazuje się, że perl alokuje trochę więcej pamięci na tablicę niż rzeczywiście zajmują przechowywane w niej dane. Domyślić się tego można badając coraz większe serie danych. Okazuje się niespodziewanie, że tylko początkowo tablica jest oszczędniejszą strukturą danych - potem przewaga przechyla się na korzyść hasza! Zbadałem serie danych od 10 do 10000 liczb (co 100) w ten sposób, że uworzyłem tablice o 100 elementach, 200, i tak dalej. Następnie tablice te zapisałem w plikach i sprawdziłem ich rozmiar. Program generujący listę liczb dla tablicy i hasza jest tutaj, a poniżej przedstawiam wykres. Czerwona "krzywa" obrazuje wielkość tablicy, a zielona wielkość hasza. Jak można zaobserwować, w pewnym miejscu hasz staje się mniejszy niż tablica zawierająca analogiczną ilość danych (powiększenie pokazuje wykres różnicy pomiędzy dwiema seriami danych).
Rys. 4. Wynik działania programu do sprawdzania wielkości tablicy i hasza.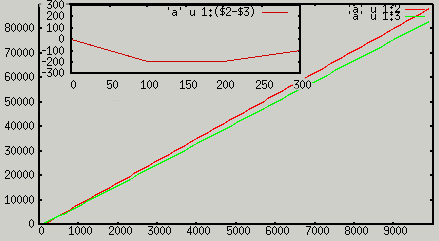 Serie danych uzyskanych w pomiarach zmian wielkości tablicy i hasza. Okazuje się, że tablica jest tylko dla niewielkich serii danych mniejsza niż hasz (dla przypadków jednowymiarowych).
Serie danych uzyskanych w pomiarach zmian wielkości tablicy i hasza. Okazuje się, że tablica jest tylko dla niewielkich serii danych mniejsza niż hasz (dla przypadków jednowymiarowych).
- Wyniki studentów, które znajdują się w tablicy tablic i były już przetwarzane w celu obliczenia średniej, można wygodniej przechowywać w haszu. Wyobraź sobie na przykład, że kluczem jest imię i nazwisko studenta, a wartością tablica z wynikami uzyskanymi w trakcie semestru. Napisz nową wersję programu do obliczania średnich osiągów studentów, na podstawie danych zawartych na znanej Ci stronie z wynikami.
Prosty program wykonujący to zadanie jest przygotowany do pobrania z serwera delta. Odpowiednie zasoby poniżej:
studenci-hash.pl
studenci-hash.txt
studenci-hash.pod - Wykorzystując hasze można eliminować powtórzenia z serii danych - dlatego, że klucze w haszu muszą być unikalne. Korzystając z tej właściwości, napisz swoją perlową wersję programu systemowego uniq. Twoja wersja może mieć przewagę nad systemową, dlatego, że nie wymaga wcześniejszego posortowania elementów! Przykładowe działanie twojego programu mogłoby wyglądać np. tak:
* Program uniq.pl, który liczy sobie w tym momencie 29 bajtów nie jest najmniejszym możliwym programem, jaki może realizować to zadanie. Spróbujesz zrobić mniejszy? :)
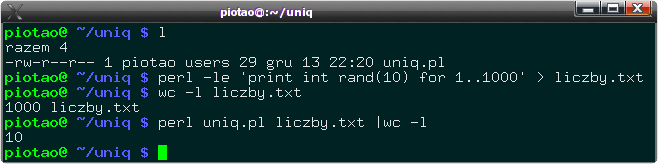 Rys. 5. Demonstracja własnego programu uniq. Wykonane jest wylistowanie katalogu przez polecenie l (alias na ls -ltrF --color=auto, a potem tworzony jest plik zawierający 1000 całkowitych liczb losowych z zakresu 0-9. Na dowód, poleceniem wc -l jest policzona liczba wierszy tego pliku (wynosi ona 1000). W takim pliku powtórzy się na pewno wszystkie 10 cyfr. Program uniq.pl filtruje ten plik i usuwa z niego duplikaty, wypisując tylko nowe, nie powtarzające się wiersze. Jak widać, powinno ich być 10 i jest dokładnie 10.
Rys. 5. Demonstracja własnego programu uniq. Wykonane jest wylistowanie katalogu przez polecenie l (alias na ls -ltrF --color=auto, a potem tworzony jest plik zawierający 1000 całkowitych liczb losowych z zakresu 0-9. Na dowód, poleceniem wc -l jest policzona liczba wierszy tego pliku (wynosi ona 1000). W takim pliku powtórzy się na pewno wszystkie 10 cyfr. Program uniq.pl filtruje ten plik i usuwa z niego duplikaty, wypisując tylko nowe, nie powtarzające się wiersze. Jak widać, powinno ich być 10 i jest dokładnie 10.
Nie trzeba było długo czekać na odzew miłośników perla - dostałem już pierwsze programy: jeden ma 28 bajtów, drugi 22 (ale nie zachowuje kolejności wierszy). Brawa dla autora 28-bajtowca (autor: R.B.)! Kto da mniej? :)
Notka z 20070105: Właśnie dostałem od autora wspomnianego 28-bajtowca wersję 18-bajtową, która nie zachowuje kolejności wierszy... Jestem pod wrażeniem :)
Rozwiązanie polega na wczytywaniu wierszy i umieszczaniu ich w haszu, aby wyeliminować powtórzenia. Dlatego program może być bardzo krótki. Oto kilka wersji:for(<>){print if !$H{$_}++}Działa wczytując każdy wiersz w pętli for do zmiennej $_, a potem wypisuje ten wiersz tylko wtedy, jeżeli zmienna $H{$_} była niezdefiniowana (a mogła być niezdefiniowana tylko raz, ponieważ jest w warunku od razu postinkrementowana, a więc kolejne odwołanie do niej będzie już zwracało wartość prawda, a po zanegowaniu przez ! fałsz, i dlatego print if wykona się tylko raz, ten jeden pierwszy. To chyba oczywiste :) Duża kompresja wielu akcji, ale bardzo pomysłowe i warte zapamiętania. (Autor: R.B.)
Inna wersja:while(<>){$A($_)++||print;}Jak widać autor (M.K.) użył pętli while, ale zasada jest prawie ta sama: wykorzystanie operacji logicznej połączonej z postinkrementacją zmiennej przechowującej wczytany wiersz w kluczu hasza. Tutaj mamy operację logicznego or wyrażoną przez operator ||. Wykonanie poleceń wewnątrz pętli dla dowolnego, nowo wczytanego wiersza może tworzyć nowy element w haszu %A lub odwoływać do poprzednio utworzonego. Jeżeli jest to pierwsze odwołanie, elementu jeszcze w haszu nie ma, dlatego wartością odwołania jest undef, a zatem operator || musi obliczyć swoją prawą stronę, w której stoi print, które oczywiście skwapliwie wypisze wczytany przed chwilą wiersz. Przy odwołaniu do wartości hasza znajduje się postinkrementacja, która spowoduje, że dopiero co uzyskana wartość undef dla tego klucza zmieni się na 1. Dlatego kolejne odwołanie nie spowoduje wykonania polecenia print, ponieważ będzie miało postać "prawda" lub..., a takie wyrażenie nie oblicza swojej prawej strony. W sumie, ten przykład można zapisać też krócej, gdyby ścigać się w ten sposób:$A{$_}++||print while<>i kod liczy sobie 23 znaki :) Zastosowanie pętli for pozwala skrócić go o jeszcze parę znaków do 21 bajtów.
Gdy użyć opcji perla -n, program można skrócić do 16 bajtów! Oto pełna postać kodu, razem z wywołaniem perla, którego nie liczymy:perl -ne '$A{$_}++||print' plik.txtOczywiście wykorzystana jest tutaj ta sama zasada co powyżej z pętlą while, z tym, że jest ona dodana niejawnie dzięki opcji -n.
Inny program nadesłał M.K. z grupy Roberta:$h{$_}=$h{$_}?1:print for<>Podobnie jak poprzednie, opiera się on o fakt niezdefiniowanej wartości otrzymywanej przy pierwszym odwołaniu do hasza z kluczem w postaci wczytanego wiersza. Tutaj jednak w każdym wykonaniu for przypisujemy do hasza pod wczytany klucz wartość albo 1 albo wynik działania operacji print (która też zwykle zwraca 1). Powoduje to efekt uboczny w postaci wypisania napisu tylko raz, gdy pojawia się on po raz pierwszy w strumieniu wczytywanych wierszy. - Dodawanie można wykonać nie tylko na liczbach, ale także na plikach. Gdyby potraktować pliki jak zbiory nie powtarzających się wierszy, w tym przypadku operacja plik1 + plik2 powinna dać sumę wierszy z obu plików. Operacja plik1 - plik2 jest ciekawsza - powinna pozwolić usunąć wiersze z pliku1 takie, jakie są w pliku2. To wbrew pozorom często wykonywana operacja, niestety, dość kłopotliwa. Napisz program, który wykonuje tego typu "działania", oraz dodatkowo tworzy część wspólną plików za pomocą działania '*'. Przykładowe zastosowanie programu mogłoby wyglądać tak:
sumuj.pl plik1.txt plik2.txt > plik_sumy.txt odejmj.pl plik1.txt plik2.txt > plik_1_bez_2.txt wspolne.pl plik1.txt plik2.txt > z_obu.txtPrzyjmij, że kolejność wierszy w plikach jest nieistotna. Nazwy plików w przypadku takiego wywołania programów, jak pokazano powyżej, umieszczane są przez perla automatycznie w specjalnej tablicy @ARGV.Zadanie to jest bardzo proste. Trzy programy, które realizują każdy z przykładów można pobrać stąd: sumuj.pl, odejmij.pl oraz wspolne.pl. Ostatni program wypisuje dokładnie to, co w plikach wystąpiło, a więc wynik będzie na pewno zawierał powtórzone wiersze, ponieważ wypisywane są wiersze występujące w obu plikach. Aby usunąć zbędne powtórzenia, można wykorzystać hasza w którym zapamiętywane będą wypisane do tej pory wiersze. Wtedy nie pojawią się one ponownie. Rozwiązanie jest w tym samym skrypcie, zakomentowane. - Wczytanie wyników polecenia zewnętrznego względem twojego programu można zrobić używając odwrotnych apostrofów (była o tym mowa na wykładzie), np. @lista_plikow = `ls -1`; Wykorzystując ten fakt, napisz program, który porówna dwa katalogi i wykaże, w którym brakuje których plików.
To proste zadanie realizuje programik, dostępny tutaj. Działa on podobnie ja wykonane powyżej programy do dodawania i usuwania wierszy z pliku, z tym, że wczytuje wyniki działania dwóch poleceń ls a następnie wypisuje ich różnice. To wszystko :) Komentarze umieszczone w kodzie powinny wyjaśnić większość pytań. Program jest bardzo prosty i nie zwraca uwagi na wielkości lub daty plików. Co więcej, nie zwraca uwagi na to, czy plik nie jest w drugim miejscu katalogiem i w przypadku zgodności nazwy nie wykaże różnicy. Prymitywne. Ale nie chodziło o nic zaawansowanego, chociaż chętne osoby mogą zgolfować jakiś mały wyczyn programistyczny i wysłać mi, żebym połamał trochę mózgownicę nad nim... :)
[c] Piotr Arłukowicz, materiały z tej strony udostępnione są na licencji GNU.