Zadania do wykładu o wyrażeniach regularnych
Uniwersytet Gdański - Instytut Matematyki - Zakład Informatyki - Strona domowaPerl: programowanie - wyrażenia regularne
Pamiętaj, że do wykonania poniższych zadań trzeba coś wiedzieć o wyrażeniach regularnych. W celu uzupełnienia swojej wiedzy, możesz zapoznać się z treścią stron:
 http://wiki.alrauna.org/index.php/Artyku%C5%82y/Wyra%C5%BCenia_regularne_w_Perlu
http://wiki.alrauna.org/index.php/Artyku%C5%82y/Wyra%C5%BCenia_regularne_w_Perlu
Strona dość opisowo i niezbyt systematycznie opisuje niektóre z perlowych zastosowań wyrażeń regularnych- http://seprob.damned.pl/regular_phrases_in_perl.txt
Krótkie i raczej pobieżne wprowadzenie z przykładami, podobny tekst do poprzedniego. - http://www.kt.agh.edu.pl/~juszkiew/perl/6.html
Bardzo krótkie ale skondensowane wprowadzenie do wyrażeń regularnych, również niekompletne, ale przydatne jako sensowna ściąga. - http://wieluk.republika.pl/strony/wzorce.html
Krótki tekst poświęcony wyrażeniom regularnym, jest niekompletny jak poprzednie, ale można przeczytać. - ../../manta/perl/wyklady/20_regexpy.php
Krótka strona o wyrażeniach regularnych którą popełniłem na potrzeby przedmiotu ZJP. Znaleźć tam można także kolejne odwołania do stron w sieci. Treści raczej niewiele.  http://www.troubleshooters.com/codecorn/littperl/perlreg.htm
http://www.troubleshooters.com/codecorn/littperl/perlreg.htm
Strona angielskojęzyczna z dość obszernym materiałem i paroma ciekawymi przykładami.- http://www.regular-expressions.info
Strona angielskojęzyczna z bardzo solidnie przygotowanym opracowaniem na temat wyrażeń regularnych. Doskonałe i prawie kompletne źródło.
Zadania do wykonania
- Napisz program, który wczytując coś od użytkownika upewnia się, że podano rzeczywiście liczbę. Można to wykorzystać np. w programie do zgadywania liczby wylosowanej przez komputer (był taki program jako jedno z poprzednich zadań). Wygodnie jest napisać funkcję, której zadaniem będzie wczytanie liczby, i która tak długo będzie pytać o liczbę, aż rzeczywiście ją otrzyma. Sprawdzenie, czy wczytano liczbę należy oczywiście wykonać za pomocą wyrażenia regularnego. Wartością funkcji powinna być wczytana liczba.
Pierwsze rozwiązanie, które przychodzi na myśl, to na przykład funkcja wczytująca ze standardowego wejścia dowolny napis tak długo, aż ten napis będzie złożony wyłącznie z cyfr:
sub wczyt { my $liczba; do{ $liczba = <STDIN>; chomp $liczba; } until $liczba =~ m{^\d+$}o; return $liczba; }Ten naiwny kod zrobi to, o co chodzi w zadaniu, ale można go oczywiście poprawić. Wystarczy napisać w programie np. takie wyrażenie:my $liczba = wczyt();i gotowe. Teraz poprawki. Pierwsze co można zrobić, to dodać jakiś dialog z użytkownikiem, to znaczy możliwość wypisania polecenia np. "Podaj liczbę: ", przed wczytaniem danych. Napis taki nie zawsze jest potrzebny, zatem pozostawiamy możliwość nie wyświetlania go, gdy nie został podany. Zmodyfikowana funkcja będzie pobierać jeden opcjonalny argument, będący tekstem do wyświetlenia przed wczytaniem liczby:sub wczyt2 { my $prośba = shift; my $liczba; do{ print $prośba if defined $prośba; $liczba = <STDIN>; chomp $liczba; } until $liczba =~ m{^\d+$}o; return $liczba; }Tak napisana funkcja działa dokładnie tak samo jak poprzednia, jeżeli wywołać ją bez argumentów:my $liczba = wczyt2();ale może być także wywołana z argumentem, np.:my $liczba = wczyt2("Podaj liczbę całkowitą: ");Wtedy, przed wczytaniem liczby pojawi się napis "Podaj liczbę całkowitą: ", a program zatrzyma się aby wczytać liczbę. Jeżeli wczytanie się nie powiedzie, napis pojawi się ponownie, aż do podania liczby (zob. rysunek poniżej).Nie jest to jednakże koniec ulepszeń, które można wykonać. Liczba, którą dopasowujemy to tylko ciąg cyfr, ale przecież liczby mogą wyglądać także inaczej, np. 1.23e+3, 0x123, bOH, itp. Generalnie nie można przewidzieć, jakiego typu liczba będzie w danym zastosowaniu potrzebna, zatem dobrym wyjściem jest umożliwienie przekazania do funkcji odpowiedniego wyrażenia regularnego, które zostanie użyte do sprawdzenia, czy podano prawidłową liczbę. W ten sposób odpada też problem tworzenia wyszukanego wzorca, do czasu, aż rzeczywiście będzie on potrzebny. Zmodyfikowana (i najbardziej uniwersalna funkcja) mogłaby wyglądać tak: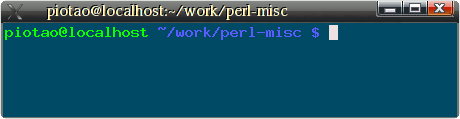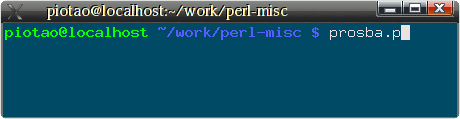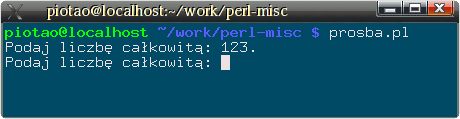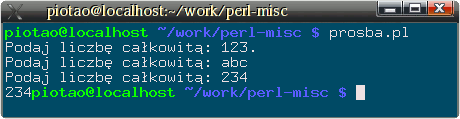
Przebieg badania programu.sub wczytaj { my $wzorzec = shift || qr/^\d+$/; # domyślnie to samo, co we wcześniejszej funkcji my $prośba = shift; my $liczba; do{ print $prośba if defined $prośba; $liczba = <STDIN>; chomp $liczba; } until $liczba =~ m{$wzorzec}; return $liczba; }Tak napisana funkcja nie ma w wierszu z dopasowaniem modyfikatora /o. Jest to celowe, ponieważ we wcześniejszych przykładach funkcji wyrażenie regularne było tylko jedno, zatem opłacało się skompilować je tylko raz. Teraz jednak wyrażenie może być za każdym razem inne, zatem jego jednorazowa kompilacja byłaby błędem. Tak napisana funkcja nie musi wczytywać liczb. Może wczytywać dowolne dane, zależnie od tego, jakie wyrażenie regularne sprawdzające podamy. Uruchomiona bez parametrów nadal będzie działała tak samo, jak pierwsza funkcja przedstawiona na początku. - Napisz wyrażenie regularne, które dopasowuje się do liczby rzeczywistej. Liczba rzeczywista może być ciągiem cyfr bez spacji, zawierających z przodu opcjonalny znak, w środku opcjonalną kropkę dziesiętną i po niej opcjonalny ciąg cyfr, zakończony opcjonalnym wykładnikiem z literą e lub E oraz opcjonalnym znakiem i ciągiem cyfr. Przykłady, które powinny się dopasować: 1, 1.0, -12.123, 1e5, 1e-50, -0.123e-12, itp.
Zadanie jest nieco mylące :) Prawidłowe wyrażenie regularne, które rzeczywiście odróżni liczbę rzeczywistą od np. całkowitej, nie powinno dopasowywać się do np. 1, ale powinno dopasować się do 1.. Ma ono w swojej pełnej (i zapewne także jeszcze niedoskonałej postaci) następującą formę:
$ereg = m{ (?:^|[-\s.\(\[\{+=\%*\$]) (?: \d+\.\d* | \d*\.\d+ ) (?: [eE][-+]?\d+ )? (?: $ | [.,\)\]\}=+\-^\%\$\s] ) }x;Wyrażenie to dopasowuje się poprawnie do liczb rzeczywistych, które dodatkowo mogą być otoczone przez nawiasy, znaki niektórych działań arytmetycznych, itp. Prawidłowym dopasowaniem będą także napisy 123+1.23, .123e-123 i inne. Umieszczenie wyrażenia regularnego w nawiasie pozwoli przechwycić liczbę i wyłuskać ją z otoczenia, w którym ona przebywa. Dlatego nie należy się bytnio martwić dopasowaniem do napisu np. 12.13.14, który także jest kwalifikowany jako prawidłowy, podobnie jak 123. 12 ale na przykład już nie 12,12.13,14 (ponieważ wymagane jest w wyrażeniu, żeby liczba kończyła się jednym z podanych znaków lub końcem napisu, podobnie z początkiem). - Za pomocą polecenia perldoc wyświetl stronę podręcznikową perl. Możesz oczywiście ją przeczytać, a w tym zadaniu należy określić liczbę wierszy, ktore zawierają słowo 'perl' w różnych kombinacjach. Wykorzystując polecenie:
perldoc perl | perl -ne 'print if /.../'stwórz takie wyrażenie regularne, aby uzyskać:- liczbę wierszy zawierających ciąg znaków perl (dosłownie, małymi literami).
- liczbę wierszy, zawierających ciąg znaków Perl
- liczbę wierszy, zawierających ciąg znaków perl bez względu na wielkość liter
- liczbę wierszy, zawierających wyłącznie słowo czteroliterowe perl
Zadanie to jest tak proste, że można potraktować je jako wypoczynek :) Oto rozwiązania:perldoc perl | perl -ne 'print if /perl/' | wc -lTo polecenie dla mojej wersji perldoca wypisuje liczbę 173. Oznacza to, że znalezionych zostało tyle wierszy zawierających słowo perl.perldoc perl | perl -ne 'print if /Perl/' | wc -lLiczba wierszy ze słowem Perl to 166.perldoc perl | perl -ne 'print if /perl/i' | wc -lTych wierszy, które zawierają słowo perl pisane dowolnymi wielkościami liter jest 202.perldoc perl | perl -ne 'print if /^perl$/' | wc -lTakich wierszy zostało znalezionych zero. Wartości poszczególnych liczb mogą się w twoim systemie różnić od otrzymancyh powyżej. - To zadanie dla statystyków. Napisz program, który wczyta plik /etc/passwd. Plik ten ma następującą postać:
piotao:x:9278:111:Piotr Arlukowicz:/home/pracown/piotao:/bin/bashKażde pole oddzielone jest od innych dwukropkiem. Pierwsze pole to login użytkownika, drugie zawierało kiedyś zakodowane hasło (teraz są one w pliku shadow), trzecie to UID, czwarte to GID, potem informacje ogólne, takie jak imię i nazwisko, dalej katalog domowy i na końcu powłoka używana przy pracy. Twój program ma przeprowadzić analizę tego pliku, i wypisać informacje:- o liczbie osób, których login składa się z czterech znaków
- o liczbie osób, których imię lub nazwisko zawiera literą a
- o liczbie osób, które nie korzystają z powłoki bash a jedynie z powłoki tcsh (konta nieaktywne należy wyeliminować)
- wymyśl swoją własną ciekawą analizę i przedstaw jej wyniki
To zadanie było podobnie jak poprzednie bardzo proste. Wystarczy do tego jednolinijkowiec, przedstawiony poniżej:perl -F: -ane '$a++ if 4==length $F[0]; $b++ if $F[4]=~/a/; $c++ if $F[6]=~/tcsh/; END{print "$a, $b, $c\n"}' passwdPrawda, że prosty? Wynikiem działania skryptu są 3 liczby, odpowiednio dla podpunktu a), b) i c), i dlatego w skrypcie tak nazywają się odpowiednie zmienne. Wykorzystany tutaj jest fakt, że plik passwd składa się z wierszy które zawierają informacje rozdzielone dwukropkiem. Najprościej taki plik "rozebrać na części" za pomocą trybu autosplit, włączonego przez opcję -a. Dodatkowo, ponieważ separatorem nie jest biały znak, ale dwukropek, do skryptu podany został argument -F, który określa wyrażenie regularne, wg. którego dane mają zostać podzielone (jest to argument do niejawnie wykonywanego split). Dzielenie odbywa się według dwukropków i dlatego mamy -F:, co w zupełności wystarcza. Pozostałe opcje (czyli -ne) powinny być już dawno zrozumiałe. Skrypt wykonuje się dla każdego wiersza, z wyjątkiem bloku END{...}, którego wykonanie następuje dopiero tuż przed zakończeniem pracy. Dlatego możemy dla każdego wiersza zebrać odpowiednie wyniki do zmiennych $a, $b i $c a potem wypisać je w bloku END. Jak widać, tylko jedna odważna osoba korzysta z powłoki tcsh. Zaś przetworzenie całego pliku passwd, który ma ponad 2500 wierszy, zajmuje perlowi ok. 0.4s (zależy to jednak od obciążenia manty). - Napisz wyrażenie regularne, które dopasuje się do wszystkich form słowa domek, a więc do "domek", "domku", "domkiem", itp. Wykorzystaj aternatywy (o których należy wcześniej poczytać).
Rozwiązaniem zadania jest wyrażenie regularne, które ma następującą postać:
m{dom(?:ek|ku|kiem|kowi)}I to wszystko. Alternatywa znajduje się w nawiasie grupującym. Jeżeli ktoś chce, może jeszcze dodać zakotwiczenia - asercje oznaczające początek i koniec napisu w wiadomych miejscach.
Kolejne zadania do wykonania
W tym zestawie czeka nas sporo zadań z dopasowania wzorców z alternatywami i klasami znakowymi. Oraz parę innych rzeczy. Warto na potrzeby trenowania swoich wyrażeń regularnych, przygotować taki mały programik pomocny do sprawdzania wielu napisów jednym wzorcem. Oto przykład (nie daję tego jako zadania, PONIEWAŻ każdy powinien umieć napisać sobie samodzielnie taki programik):
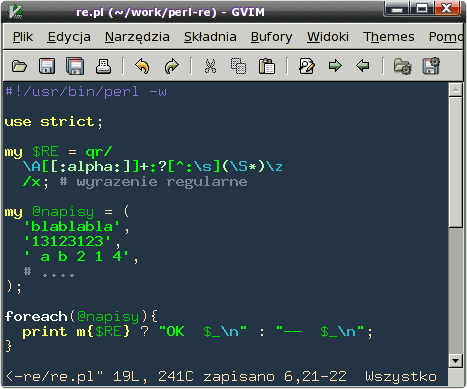 Przykład programu do budowania i "trenowania" swoich wyrażeń regularnych. Spróbuj dla wprawy przed jego napisaniem przemyśleć i przewidzieć, który napis z zebranych w tablicy @napisy może zostać dopasowany, i ewentualnie dlaczego.
Przykład programu do budowania i "trenowania" swoich wyrażeń regularnych. Spróbuj dla wprawy przed jego napisaniem przemyśleć i przewidzieć, który napis z zebranych w tablicy @napisy może zostać dopasowany, i ewentualnie dlaczego.- To zadanie jest trywialne, dlatego można je potraktować jako rozgrzewkę: napisz wyrażenie regularne, które dopasuje dowolną liczbę szesnastkową. Oczywiście sprawdź co najmniej kilka przypadków. Dobre wyrażenie NIE dopasuje się do pustego napisu, napisu w formie 0x123 itp.
Zakładamy oczywiście że liczba szesnastkowa składać się może wyłącznie z cyfr 0-9 oraz liter A-Fa-f. Wtedy wystarczy napisać po prostu:
m{[\dA-Fa-f]+}i gotowe. Oczywiście takie wyrażenie dopasuje się do napisu w postaci 123abcxyz, ale na to jest także rada: wystarczy wstawić znaki zakotwiczenia aby liczba zaczynała się na początku napisu i kończyła na końcu:m{^[\dA-Fa-f]+$} - Napisz program który dopasowuje polskie kody pocztowe. Kod pocztowy na postać AB-CDE, gdzie nie mogą występować spacje ani inne znaki nie będące cyframi.
Wyrażenie regularne które dopasowuje się do kodu może mieć taką oto prostą postać:
m{\d\d-\d{3}} - Napisz wzorzec, który dopasowuje się do numeru IPv4 w postaci tekstowej, czyli np. do 123.123.123.123. Zadbaj o to, aby NIE dopasowały się żadne nieprawidłowe numery, np. 123.456.789.000. Pamiętaj także o odpowiednich przypadkach szczególnych, np. 0.0.0.0 jest poprawnym adresem IP.
Budowę takiego wyrażenia można rozpocząć od najprostszego przypadku, czyli np. zauważenia, że adres IP składa się z 4 liczb całkowitych oddzielonych kropkami. Taki układ cyfr i kropek można dopasować wzorcem m{\d+\.\d+\.\d+\.\d+}, lub zapisanym nieco bardziej sprytnie m{(?:\d+\.){3}\d+}. Taki wzorzec jest jednak zbyt pobłażliwy w przypadku adresów IP, ponieważ w IPv4 liczby te mogą mieć wartości jedynie od 0 do 255, a dopasuje się np. 666.666.66666.666666666 bez problemu. Dlatego pierwszym organiczeniem mogłoby być wymuszenie długości ciągów cyfr, w postaci np. m{(?:\d{1,3}\.){3}\d{1,3}}. Nadal jednak nie ma kontroli nad rzeczywistymi wartościami liczb do których dopasowywany jest wzorzec, zatem taki "numer IP" będzie dopasowany: 666.666.666.555. Trzeba wprowadzić analizę wartości, ale wzorce nie wspierają tego w prosty sposób. Rozwiązaniem jest skorzystanie z kodu we wzorcu, lub napisanie reguły nie pozwalającej na istnienie liczby większej niż 255. Ta druga metoda jest bardziej tradycyjna. Należy zacząć od przypadków krańcowych, to znaczy od zauważenia, że liczba może być jedno-, dwu- lub trzycyfrowa. Liczba jedno lub dwucyfrowa może być dowolna, ponieważ nie przekroczy 255. W przypadku liczby trzycyfrowej istnieje przypadek, gdy zaczyna się ona od 1 (wartości 100-ileś) oraz od 2 (wartości od 200 do 255). Trzeba w wyrażeniu opisać te przypadki. Zatem, liczba jednocyfrowa to /\d/, dwucyfrowa to /\d\d/, natomiast trzycyfrowa to wybór z /1\d\d/, oraz /2-coś/. Przypadków dla liczb z /2/ką ma początku jest więcej, ponieważ możemy mieć liczby z zakresu 200-249 opisane przez wyrażenie /2[0-4]\d/ oraz liczby z zakresu 250-255, opisane przez wyrażenie /25[0-5]/. Składając do jednego wyrażenia regularnego te wszystkie fragmenty, otrzymujemy ciąg alternatyw, przy czym dobrze najdłuższe umieścić najpierw: /25[0-5]|2[0-4]\d|1\d\d|\d\d|\d/. Wyrażenie to zawiera trochę powtórzeń, np. fragment \d\d|\d można przedstawić jako /\d\d?/ a fragment /1\d\d/ można dołączyć do poprzedniego uzyskując /1?\d\d?/. Tak napisane wyrażenie dla jednej liczby wygląda tak:
/25[0-5]|2[0-4]\d|1?\d\d?/Należy teraz dopisać na jego końcu kropkę i całość powtórzyć trzy razy, na końcu wstawiając jeszcze jedno takie podwyrażenie dopasowujące ostatnią liczbę:m{(?:(?:25[0-5]|2[0-4]\d|1?\d\d?)\.){3}(?:25[0-5]|2[0-4]\d|1?\d\d?)I to wszystko. Dopasowane zostaną tylko adresy w wersji IPv4, a wyrażenie jest względnie krótkie. Czytelniejszy kod można uzyskać składając je z fragmentów, np.:my $liczba = qr{25[0-5]|2[0-4]\d|1?\d\d?}; my $ereg = qr{(?:$liczba\.){3}$liczba}; - Sprawdź, czy data w postaci RRRR-MM-DD jest poprawną datą leżącą w obszarze drugiego kwartału roku w zakresie od 1900 do 2012 (podobno wtedy nastąpi jakiś koniec świata).
Zadanie to jest swoistą modyfikacją poprzedniego. Objawia się w nim pewna słabość wyrażeń regularnych, która polega na tym, że bardzo proste sprawdzenie danej wartości numeryczne jest raczej trudno wykonalne. Wyrażenia działają na dopasowaniu znaków, a znalezienie wzorca który dopasowuje liczby z pewnego zakresu bywa często trudne. Dlatego ten przykład można rozwiązać stosując rozszerzenia wyrażeń regularnych, polegające na wstawkach kodu perla. Oczywiście rozwiązanie klasyczne, prezentowane w zadaniu powyżej także da się wykonać, chciałbym jednak pokazać obie drogi dlatego teraz czas na nieco bardziej zaawansowane dopasowywanie :) Analizę warto rozpocząć od zauważenia, że daty o które chodzi opisuje prosty wzór: /\d{4}-\d\d-\d\d/. Taki wzór wystarczy, aby dopasować prawidłowe daty, niestety, dopasowane mogą także zostać daty nieprawidłowe (np. 9999-00-00). Dlatego każdy z elementów daty zawierający cyfry przechwycimy w nawiasy i wykorzystamy wstawiony za nimi kod perla w celu określenia wartości liczbowej przechwyconych cyfr: /(\d{4})•-(\d\d)•-(\d\d)•/. W miejsce czerwonych kropek wstawimy kod perla, który umieszczony tam będzie za pomocą asercji (??{...}). Wynikiem działania tej asercji będzie wyrażenie regularne (dlatego jest podwójny ??), które zostanie skompilowane i wstawione w jej miejsce. Kod perla sprawdzi wartość liczby dopasowanej w poprzedzającym nawiasie (wartość ta przechwycona jest przez perla do zmiennej $^N), po czym wygeneruje albo wzorzec, który dopasuje się do wszystkiego (jeżeli liczba jest OK) albo do niczego (jeżeli liczba nie spełnia warunków zadania). Wzorzec, który dopasowuje się do wszystkiego, to wzorzec pusty - // (puste miejsce zawsze się dopasuje do dowolnego napisu). Wzorzec, który nigdy się nie dopasuje, to połączenie sprzeczności, np. granicy słowa z nie-granicą słowa - /\b\B/. Dysponując takimi możliwościami, kod perla możemy zapisać jako instrukcję if:
if( $^N >= 1900 and $^N <= 2012 ){ qr{} } else { qr{\b\B} }Taki kod można skrócić używając operatora warunkowego:($N >= 1900 and $^N <= 2012) ? qr{} : qr{\B\b}I gotowe wyrażenie regularne wygląda wtedy tak:qr{ (\d{4}) (??{ ($^N>=1900 and $^N <= 2012) ? qr// : qr/\b\B/ }) - (\d\d?) (??{ $tmp=$^N; #dodatkowa zmienna (poprawka by M.K.) (4 <= $^N and $^N <= 6) ? qr// : qr/\b\B/ }) - (\d\d?) (??{ (0 < $^N and $^N <= 30 + $tmp % 2 ) ? qr// : qr/\b\B/ # w maju jest 31 dni, jest to miesiąc nieparzysty (by M.K.) }) }xTak zbudowane wyrażenie poprawnie dopasowuje się np. do takich danych testowych (litery OK oznaczają dopasowanie:-- - 1900-01-02 -- - 1900-02-3 -- - 1900-02-2 -- - 1900-02-1 -- - 1900-02-33 -- - 1901-03-23 OK - 1901-04-23 OK - 1901-05-23 OK - 1901-06-23 -- - 2012-01-23 -- - 2012-02-23 -- - 2012-03-23 OK - 2012-04-23 OK - 2012-05-23 OK - 2012-06-23Poprawki zaproponował jeden z moich lepszych studentów (M.K.) za co dziękuję. :) Nadal mogą być jakieś ukryte błędy! :) - Napisz wzorzec, który dopasowuje się do gdańskich numerów telefonów podawanych w postaci: 058-xx-yy-zz ewentualnie z numerem kierunkowym Polski (+48), lub innych kombinacji, które opracuj sam. Następnie weź udział w konkursie - poproś kolegów lub koleżanki o sprawdzenie twojego rozwiązania (oraz sam przedstaw im swoje), i przetestujcie krzyżowo wszystkie swoje przykłady numerów telefonicznych.
Taki wzorzec może mieć np. postać daną wyrażeniem:
$ereg = qr/(?:\+?48-?)?\(?0?58\)?-\d\d-?\d\d-?\d\d/;Można go wykorzystać do sprawdzenia, czy w danym tekście znajduje się numer telefonu, ale wtedy warto takie wyrażenie regularne otoczyć np. nie-liczbami (aby np. nie nastąpiło dopasowanie do większego fragmentu będącego ciągiem cyfr przypominających numer telefonu tylko w swoim fragmencie). Wydobycie takich numerów z całego tekstu możliwe będzie przez otoczenie wyrażenia regularnego nawiasem i wykonanie go w maszynie dopasowującej wszystkie wystąpienia, umieszczonej w konteście listy (aby odebrać wszystkie przechwycone dopasowania). - Napisz wzorzec, który dopasowuje się do typowego, w najczęściej spotykanej postaci, adresu E-Mail. Adres taki na postać login@domena, np. "Billy" <Bill.Gatez@microsoft.com> (sucker). Tekst w nawiasach po adresie mailowym to komentarz dozwolony przez RFC#773 (ale nie radzę budować wyrażenia spełniającego całą specyfikację) jeżeli chcecie skończyć przedmiot jeszcze w tym roku :)
- Napisz wzorzec, który dopasowuje się do adresu strony internetowej (i tylko strony internetowej). Możesz dla bezpieczeństwa (na początku) przyjąć, że strona ta nie jest kodowana w postaci znaków szestnastkowych i że w urlu nie ma znaków diakrytycznych. Przykładowy adres: http://zrobie.to.albo-nie.pl/index.php?a=2&sid=11ab21. Dla twardzieli polecam krótkie zapoznanie się ze specyfikacją (też może się zrobić słabo), dostępną pod adresem RFC#1738. Można się z tego dokumentu dowiedzieć na przykład dlaczego domena nigdy nie może zostać pomylona z adresem IP.
Zadania dodatkowe
W tej grupie zadań polecam trochę trudniejsze problemy, których rozwiązanie wcale nie musi być w 100% możliwe. Niemniej, należy do niego się zbliżyć tak bardzo, jak to tylko jest możliwe, aby uzyskać jak najlepsze efekty. W przypadku zadań oznaczonych gwiazdką należy mieć na uwadze, że są to zadania trochę trudniejsze od tych, jakie zwykle zadaję. W zamian za to, można rozwiązać te zadania w nieprzekraczalnym terminie 20070311:2359 i podesłać mi rozwiązania z komentarzami, PODem, przykładami użycia i inną dokumentacją, jak w przypadku dowolnych innych projektów perlowych. Gdy sprawdzę programy i dołączone pliki, dodam do puli punktów bonusowych stosowną ich ilość. Uwaga - to propozycja, nie zalecenie. Dotyczy tylko chętnych :)
- (* 1pkt) Mając daną listę adresów internetowych razem z ich opisem, w postaci <a href="...adres...">...opis...</a>, napisz funkcję, która pobiera taką listę i zwraca listę posortowaną według opisów. Taka funkcja przydać Ci się może do sortowania adresów internetowych, np. w swoich zakładkach. Możesz wykorzystać listę adresów umieszczoną w tym pliku (brudna lista), lub poszukać ich na dowolnej stronie internetowej. Oczywiście musisz podjąć decyzję, które urle są warte sortowania, a które nie, oraz sortować rzeczywiście TYLKO te, które mają opis tekstowy, a nie np. w postaci obrazka... :) Zatem funkcja taka może być także filterm, który odrzuca wszystko, co nie wygląda jak przyzwoity, prosty url :)
- (* 2pkt) Praktyczne i dość trudne zadanie, to napisanie programu - robota, który grzebie w internecie w poszukiwaniu stron o zadanej treści. Napisanie w perlu takiego robota jest bardzo łatwe, a ważnym elementem takiego programu jest opracowanie odpowiednich wyrażeń regularnych. W tym zadaniu należy napisać program, który z danej strony HTML wydobędzie wszystkie adresy internetowe, prowadzące do innych stron. Należy pominąć adresy prowadzące do obrazków (a więc te w tagach <img src="...", oraz inne, typu location, action, itp. - akceptujemy jedynie href'y). Dla osób chcących mieć sporą listę adresów, polecam stronę np. z raportami technicznymi W3C. Jest tam sporo urli i są nie w postaci prostego adresu http, ale jako ładny opis. Wynikiem działania programu powinna być lista adresów wypisanych w kolejności znajdowania, w postaci źródła html, czyli podobnego jak w zadaniu powyżej.
- (* 2pkt) Jednym z uciążliwych cech internetu jest zjawisko spamu. Polega ono na otrzymywaniu niechcianych wiadomości kierowanych wprost do naszej skrzynki pocztowej (i nie tylko - ostatnio proceder ten rozszerza się także poza świat wirtualny). Adres naszej poczty z reguły znajdowany jest w sieci, i w tym zadaniu należy sobie wyobrazić, że zatrudniono Ciebie w największej spamerskiej firmie świata. To, co należy zrobić, to napisać program do wyszukiwania adresów mailowych zawartych w dowolnej stronie WWW lub w dowolnym tekście. Strony do przeszukania należy oczywiście pobrać z internetu. Dla niezdecydowanych polecam stronę manty z listą stron domowych albo jakieś np. blogi lub archiwa grup dyskusyjnych. Należy przeszukać je np. do drugiego poziomu w głąb no i wydobyć adresy do spamowania! Stronę WWW aktualnie przetwarzaną można pobrać do lokalnej zmiennej w perlu za pomocą np. biblioteki LWP::Simple. Robot szukający adresów może zawierać pewną instrukcję spowalniającą (np. co jakiś czas wykonywane polecenie sleep 5 zatrzyma program na 5 sekund i da odetchnąć serwerowi WWW z którego pobieracie stronę) :) Dobrze skonfigurowane serwery WWW mogą odmówić połączenia jeżeli wasz program będzie zbyt intensywnie pobierał dane.
- Sprawdź, w jaki sposób można dopasować w perlu napis, przed którym NIE występuje inny napis. Napisz takie wyrażenie regularne, które pasuje do zdania "... aaa bbb 123 ..." ale nie pasuje do zdania "... aaa bbb bbb 123 ..."
- Napisz wzorzec, który usunie wszystkie powtórzenia wyrazów i zastąpi je jednym ich wystąpieniem. Na przykład napis "Jestem po po po po po egzaminie" ma się zamienić w napis "Jestem po egzaminie". Jeżeli uda Ci się takie wyrażenie i będzie działać, spróbuj zmierzyć się z problemem zamiany powtórzeń przeplatanych, np. zdanie "umowilem sie na go na go na godzine 9" powinno się zamienić w napis "umowilem sie na godzine 9".
- Napisz wyrażenie regularne, które pasuje tylko do wyrazu "struś", po którym występuje słowo "pędziwiatr" (bez skojarzeń) :) Użyj asercji przewidujących.
Jeszcze kilka zadań dodatkowych
Tym razem do wykonania jest kilka zadań ogólnych w których należy połączyć umiejętności z różnych dziedzin perlowego programowania. Należy przygotować moduły w których znajdą się funkcje parsujące różnego typu. Zadania te nie są trudne... :)
- Napisz moduł w którym umieścisz funkcje obsługujące pliki INI. Typowy plik INI ma następujący format:
; komentarz po znaku średnika [sekcja] ; nagłówek sekcji grupującej opcje w nawiasach [ ... ] opcja = wartość ; zestaw opcji w formie klucz=>wartośćTwój nowy, błyszczący i gotowy do użycia moduł powinien zawierać:- funkcje obsługi plików: wczytanie, zapis, tworzenie, itp.
- funkcje obsługi danych: dodanie/usunięcie sekcji/klucza, obsługa powtórzeń, wyszukanie danych, itp.
- jasno i czytelnie napisaną dokumentację
- Napisz moduł do parsowania plików CSV (RFC4180). Istnieje kilka odmian takich plików. Przyjmij na potrzeby tego ćwiczenia, że plik taki ma prosty format tekstowy, w którym pierwszy wiersz zawiera słowa oddzielone tabulatorami (znakami \t). Słowa te to nazwy kolumn danych. W pozostałych wierszach pliku znajdują się dane oddzielone od siebie znakami tabulacji. Dane te nie zawierają znaków tabulacji ani znaków nowego wiersza. Zasady dla tego zadania są takie same: utwórz moduł do przetwarzania takich plików, i zadbaj o prawidłowe napisanie funkcji obsługujących zarówno pliki CSV jak i dane CSV wczytywane/zapisywane do/z tych plików. Przykładowy plik CSV do pobrania można zessać stad: [dane.csv, 3.2kB]. Zainteresowani szczegółami technicznymi formatu CSV mogą zerknąć tutaj (włos się jeży na głowie).
- Napisz parser plików XML, działający na zasadzie przetwarzania strumieniowego, to znaczy w taki sposób, aby przy każdym wywołaniu pewnej funkcji, którą napiszesz, otrzymywać tylko jeden rekord ograniczony wybranymi tagami. Przykładowo:
while( $record = getRecord($xml_data, 'student') ){ ... }kod tego rodzaju miałby czytać plik XML jako strumień tekstu i niezależnie od tego, jaka byłaby struktura rekordów, ich kolejność oraz ich poziom zagłębienia, zwracałby zawsze kolejny wczytany rekord o podanej nazwie. Zadbaj o odpowiednią dokumentację swojego modułu oraz pozostałe rzeczy. Nie korzystaj z żadnych modułów z CPAN parsujących XMLa. Przyjmij, że XML nie zawiera danych CDATA ani cytowań samego XMLa. Możesz zignorować wszystkie białe znaki i nie zachowywać ich formatowania. Uwzględnij fakt, że w jednym wierszu możesz wczytać wiele takich samych rekordów, jednak wywołanie twojej funkcji może zwrócić tylko pojedynczy, kolejny rekord. Wskazówka: użyj wewnętrznego bufora do przechowywania danych. - Napisz moduł do parsowania i obróbki plików VCARD, zawierających wizytówki używane przez np. książki adresowe, Outlook, oraz różne programy zarządzające kalendarzem i czasem. Moduł ten powinien umożliwiać import/export plików do VCARD, tworzenie nowych wizytówek oraz przetwarzanie wielu wizytówek zawartych w jednym pliku. Pewne szczegóły na temat tego formatu możesz znaleźć tutaj. Jeżeli dysponujesz telefonem komórkowym, to kontakty zapisane w nim mogą być zgrane w postaci plików VCARD właśnie. Napisanie modułu do ich obsługi umożliwi Ci programowe zarządzanie swoimi kontaktami. Przykładowa wizytówka jest plikiem tekstowym który może mieć np. taką zawartość:
BEGIN:VCARD VERSION:2.1 N:;CHARSET=UTF-7:Ar+AUI-ukowicz Piotr; TEL;CELL:+0066600666000 TEL;WORK:2505 ORG:UG TITLE:DR UID:4A74455F-C577-4365-90AA-87F4C1A78276 X-IRMC-LUID:000200000050 END:VCARD - Jeżeli znasz jakiś format pliku, który uznasz za warty oprogramowania, napisz do niego parser lub moduł obsługi. Ciekawe projekty mogą zostać nagrodzone jakimś małym dodatkowym punktem bonusowym... Chociaż kto wie...