Zadania do wykładu o uruchamianiu perla
Uniwersytet Gdański - Instytut Matematyki - Zakład Informatyki - Strona domowaPerl: programowanie - Zadania do wykładu o uruchamianiu perla
Większość odpowiedzi i podpowiedzi do zebranych poniżej zadań można znaleźć w podręczniku systemowym do perla - dostępnym po poleceniu perldoc perlrun.
- Zbadaj, jakimi powłokami dysponuje twój system (w tym przypadku manta). Jeżeli masz powłokę typu bash, to określ, czy jest jeszcze np. csh, tcsh, zsh i inne. Napisz następnie prosty skrypt typu "Hello world", który uruchamia się niezależnie od tego, gdzie znajduje się perl, oraz w jakiej powłoce akurat pracujesz.
Zadanie to można było rozwiązać na kilka sposobów, ale wystarczyło sprawdzić w możliwie najprostszy sposób. Prawie każdy pracuje na pracowni w środowisku powłoki bash, w której domyślnie działa dopełnianie wpisanych słów po napisaniu kilku pierwszych liter i naciśnięciu klawisza TAB (gdy jest tylko jedna możliwość dopełnienia, wystarczy raz, gdy możliwości jest więcej, trzeba nacisnąć klawisz TAB dwa razy). Zatem napisanie np. ba i naciśnięcie TAB podpowie, czy jest zainstalowany bash. Tak samo z csh, tcsh, zsh, itp. Oczywiście zamiast wymyślać, jakie jeszcze nazwy mogą mieć powłoki, można sprawdzić to w sposób pewny. Jest bowiem specjalny plik w systemie, w którym spisane są wszystkie powłoki, jakie zainstalowano (nie znaczy to, że wszystkie można uruchomić). Ten plik to /etc/shells. Wyświetlenie jego zawartości po poleceniu np. cat, pokazuje od razu listę powłok:
/bin/ksh /bin/sh /bin/bash /bin/rbash /bin/tcsh /bin/csh /bin/ch /bin/falseDalsza część odpowiedzi na zadanie powinna zawierać sposób ustalenia, czy plik leżący w /bin/bash to prawdziwy bash, czy np. link symboliczny do /bin/sh (jest to często stosowana praktyka - ta i podobne do niej w celu zmiany jednej powłoki na drugą dla całego systemu). Aby sprawdzić, czy nie jest to link symboliczny, wystarczy wywołać polecenie ls -lF /bin/bash, które odpowie poprzez zaznaczenie typu wyświetlanego pliku. Jeżeli będzie to link symboliczny, dostaniemy także informację, do czego on prowadzi (lub na co wskazuje):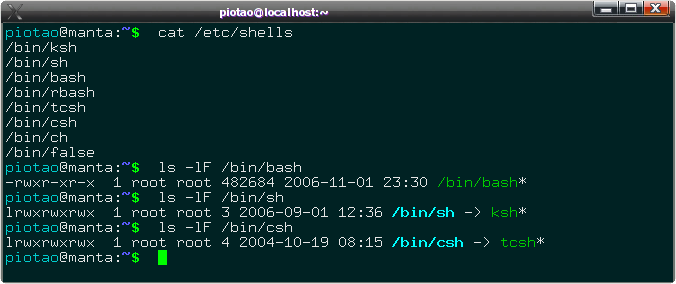 Rys. 1. Znalezione powłoki oraz wyniki testowania niektórych z nich. Polecenie ls -lF pokazuje na co wskazuje link symboliczny, jeżeli plik jest linkiem. Zwykły plik wykonywalny jest wyświetlany jako nazwa ze znakiem gwiazdki, przy czym gwiazdka nie jest częścią nazwy.
Rys. 1. Znalezione powłoki oraz wyniki testowania niektórych z nich. Polecenie ls -lF pokazuje na co wskazuje link symboliczny, jeżeli plik jest linkiem. Zwykły plik wykonywalny jest wyświetlany jako nazwa ze znakiem gwiazdki, przy czym gwiazdka nie jest częścią nazwy.
- * To zadanie dla hardcorowców (nieobowiązkowe dla początkujących): napisz taką procedurę uruchomienia skryptu w perlu, która uruchomi skrypt nawet jeżeli NIE jest on na ścieżce wykonywalnej i uruchamiany jest z katalogu, w którym się on nie znajduje.
To zadanie na jakieś 10-20 minut pracy (niedużo myślenia). Poniżej jedno z rozwiązań, znalezione przez wykładowcę we wspomnianym czasie, a pod spodem wyjaśnienie. Oczywiście - można zrobić to także inaczej, ale rozwiązanie spełnia warunki zadania, gdyż skrypt uruchamia się w bashu oraz w tcsh. Na poniższym rysunku do znaku zgłoszenia dodano dodatkowo numer wykonywanego polecenia, aby potem łatwiej było objaśnić co się po kolei dzieje:Wyjaśnienia:
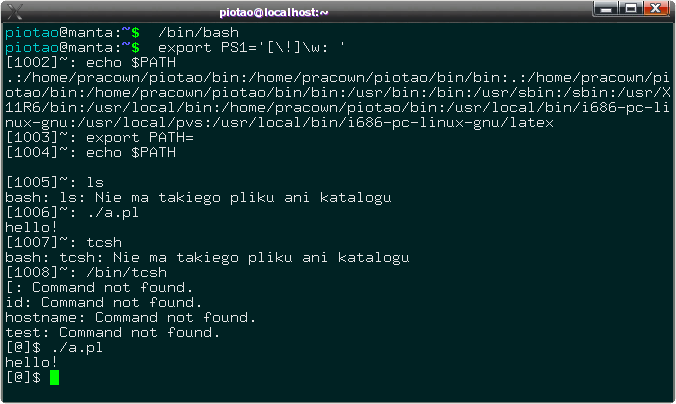 Rys. 2. Przebieg rozwiązania zadania. Polecenia podawane po kolei z widocznym numerem, aby łatwiej można było wyjaśnić, co się dzieje.
Rys. 2. Przebieg rozwiązania zadania. Polecenia podawane po kolei z widocznym numerem, aby łatwiej można było wyjaśnić, co się dzieje.
• W pierwszym wierszu uruchamiamy (dla pewności) interpreter bash, pisząc polecenie bash :) Spowoduje to pracę powłoki w powłoce, i tylko ta ostatnia analizuje i wykonuje polecenia (poprzednie czekają aż zakończy się ta uruchomiona). Uruchomienie to na pozór niczego wizualnie nie zmienia - znak zgłoszenia systemu jest taki sam, jak był (bo pracowaliśmy już wcześniej w takiej powłoce).
• W następnym wierszu ustawiamy tzw. zmienną środowiskową o nazwie PS1. Jest to charakterystyczna dla basha zmienna, której treść definiuje wygląd zgłoszenia systemowego. To, co ustawiamy to wzór napisu, który będzie pojawiał się w terminalu po każdym poleceniu. W tym przypadku będzie to numer polecenia w kwadratowych nawiasach oraz następująca po nim bieżąca ścieżka z dwukropkiem na końcu. Nie ma tu żadnej magii, a ten krok dla rozwiązania jest zbędny - chciałem tylko, aby kolejne linie poleceń były dalej numerowane, dlatego ustawiłem w taki sposób terminal. Od momentu ustawienia zmiennej PS1, bash wykorzystuje ją do wypisywania znaku zgłoszenia, i widać w następnej linii, że powłoka czeka na wpisanie polecenia o numerze 1002. Dużo? Ustaw sobie i zobacz jak to wygląda u Ciebie! :)
• Wiersz 1002: wyświetlamy kontrolnie zmienną powłoki o nazwie $PATH. Zmienna ta zawiera po prostu listę ścieżek, które zostają przeszukane gdy wpisujemy jakieś polecenie. Na przykład gdy wpisujemy bc (kalkulator), to przeszukiwana jest ścieżka ., potem w katalogu domowym bin, bin/bin, potem jeszcze raz (hm, niezbyt fortunnie ustawione mam ścieżki), potem /usr/bin i tam znaleziony zostaje program o nazwie bc. Następne ścieżki nie są przeszukiwane. Gdyby w katalogu bieżącym znajdował się program bc, to uruchomiłby się właśnie ten, a nie wersja systemowa z /usr/bin/bc. OK, zatem ścieżki są zdefiniowane, a w zadaniu jest mowa o tym, aby perl nie był na takiej ścieżce. Dlatego w poleceniu 1003 ścieżka jest ustawiana na napis pusty, i zwykłe wywołania poleceń przestają wtedy działać (np. bc się już nie uruchomi).
• Wiersz 1003: ustawiamy ścieżkę na wartość pustą. Od tego momentu może ci się wydawać, że polecenia przestają działać, ale to nieprawda. Trzeba je tylko poprzedzić ścieżką, ponieważ system zwyczajnie ich nie będzie znajdował. • Wiersz 1004: wypisujemy dla pewności nową wartość zmiennej $PATH. Jak widać, wartość ta jest pusta (nowa linia wstawiana jest przez polecenie echo).
• Wiersz 1005: uruchamiamy na próbę polecenie ls. Jak widać, polecenie to nie zostaje znalezione (aby działało, należałoby napisać /bin/ls. W takim stanie system jest gotowy do uruchomienia skryptu - perl nie zostanie znaleziony, ponieważ nie znajduje się na ścieżce wyszukiwania. Dlatego sam skrypt musi zadbać o znalezienie perla.
• Wiersz 1006: uruchamiamy skrypt (znajduje się on w pliku a.pl. Musimy podać ścieżkę do niego (lokalny katalog po prostu) - stąd bierze się ./. System znajduje skrypt i uruchamia go w bieżącej powłoce, a następnie wykonuje. Słowo, które się wypisało pochodzi jednak już od perla, który został znaleziony w odpowiednim miejscu, uruchomiony i zmuszony do wykonania skryptu.
• Wiersz 1007: uruchamiamy na próbę powłokę tcsh. Jak widać, nie została znaleziona, ponieważ nie określono ścieżki dostępu do niej.
• Wiersz 1008: uruchamiamy powłokę tcsh z podaniem ścieżki. Teraz uruchamia się ona, ale dodatkowo jej uruchomieniu towarzyszy uruchomienie kilku innych poleceń (zdefiniowanych w .tcshrc, .cshrc lub /etc/csh.cshrc - zależnie od tego, który plik istnieje). Ponieważ nie mamy ustawionych ścieżek, pojawiają się komunikaty, że poleceń nie znaleziono.
• Wiersz [@]$: (sekwencja [@]$ to znak zgłoszenia jaki ustawił się w tcsh. Gdyby znalezione zostały polecenia uruchamiane wcześniej przy starcie powłoki, znak ten wyglądałby np. tak: [piotao@manta]$. Uruchamiamy nasz skrypt, pisząc ponownie ./a.pl. I znowu pojawia się słowo wypisane przez perla! Czyli skrypt jak widać działa.
OK, czas zaprezentować co takiego magicznego kryje się w skrypcie, że startuje on nawet wtedy, gdy perla nie ma ścieżce, a sam skrypt również nie leży na ścieżce wykonywalnej (nie leży dlatego, że usunęliśmy zawartość zmiennej $PATH!). Skrypt jest bardzo prosty. Punktem wyjścia jest podana w perldoc perlrun receptura na uruchomienie programu perlowego niezależnie od środowiska. Jest to zapis podany w postaci kodu:#!/bin/sh -- # -*- perl -*- -p eval 'exec perl -wS $0 ${1+"$@"}' if $running_under_some_shellPolecenia te nie zadziałają na mancie, z racji tego, że jest to trochę inny system. W każdym razie, pierwszą linię należy opuścić, ponieważ to głównie ona zakłóca uruchomienie. Druga linia wykorzystuje wbudowane w powłokę polecenie eval, które pobiera argument w postaci pojedynczego napisu i wykonuje go, jakby w obudowanym, podrzędnym procesie (perl także ma taką funkcję). Wykonane zatem zostaje polecenie perl -wS... i tak dalej. Polecenie to nakazuje perlowi wykonać skrypt podany mu w wierszu poleceń jako argument, a skrypt otrzymuje następne argumenty z wiersza polecenia jako swoje argumenty (wiem że to brzmi zabawnie, ale tak właśnie się dzieje). Opcja -w to włączenie komunikatów o błędach, a -S to nakaz przeszukania ścieżek w celu odnalezienia skryptu (w tym zadaniu skrypt ma właśnie nie leżeć na ścieżkach poszukiwania). Kolejność wywołań jest mniej więcej taka:
w powłoce: skrypt.pl (to nazwa przykładowa) eval 'exec perl .....' perl -sW skrypt.pl (skrypt.pl wchodzi tu zamiast $0) skrypt.pl (skrypt.pl uruchomiony w perlu) eval '...' if 0; (wykonane przez perla, czyli zignorowane) ... (reszta kodu)Taka jest teoria, natomiast program, który realizuje powyższy przykład jest troszkę inaczej zbudowany. Główna różnica polega na tym, że wobec braku ścieżek z $PATH, trzeba perla odszukać (za pomocą find). Opcji -S także można już nie podawać, bo perl i tak niczego nie znajdzie, zamiast tego, podawana jest ścieżka do katalogu bieżącego, w którym (jak zakładamy) znajduje się skrypt. Bez tego założenia, skryptu należałoby szukać podobnie jak perla za pomocą drugiego polecenia find (w tym przykładzie już tego nie dodawałem). Oto treść skryptu:eval 'exec `/usr/bin/find /usr/{bin,local/bin} -name perl -prune -print` `pwd`/$0 $@' if 1==0; use strict; print "hello!\n";Kod ten jest dość prosty. Działa w sh, csh, tcsh, ksh i bash na mancie (ale należy pamiętać, że tak naprawdę to tylko trzy powłoki, nie pięć).- Wykonaj polecenie find . -print0 aby się przekonać co będzie jego wynikiem. Napisz następnie filtr perlowy, który spowoduje wyświetlenie wszystkich nazw plików w postaci listy jednokolumnowej. Jest to zadanie na użycie opcji uruchomieniowej perla -0 (minus zero). Oraz paru innych :)
Program może mieć np. taką postać:find . -print0 | perl -ln0e 'print'Albo taką:find . -print0 | perl -lp0e ''Wyjaśnienie jest bardzo proste, jeżeli wie się, co robią poszczególne opcje podane jako argumenty do perla. W obu przypadkach do perla skierowane są wyniki działania polecenia find, które generuje zestaw napisów oddzielonych znakiem bajtowym o kodzie 0. Napisy te zawierają nazwy plików i ścieżki do nich. Gdy wypisać wynik działania find na terminal, widać jeden połączony długi napis (zależy od terminala) - w którym (na mancie niewidoczne) ustawione są separatory ze znaków pustych (o kodzie 0). Taki napis jest przez perla wczytywany ze standardowego wejścia, i przetwarzany. Opcja -l nakazuje perlowi wypisać znak nowej linii po każdym wykonaniu instrukcji print. Opcja -n w pierwszym przykładzie powoduje wykonanie kodu podanego po opcji -e dla każdego wczytanego wiersza. Opcja -p (w drugim przykładzie) powoduje przetworzenie wszystkich wierszy otrzymanych na wejściu oraz wypisanie w przypadku każdego z nich wartości zmiennej domyślnej ($_, która zawiera początkowo każdy wczytany wiersz). Prawde mówiąc, robi ona to samo, co robi opcja -n ale dodatkowo przetwarzany wiersz zostaje automatycznie wypisany. Patrząc na wyniki działania polecenia find może się wydawać, że perl wczytałby cały tekst z find jako jeden wiersz, ponieważ nie ma w nim znaków nowej linii, które w naturalny sposób oddzielają wiersze. Ale w tym przypadku zostało to zmienione: find oddziela osobne wiersze znakiem o kodzie 0 (co wygląda jak tekst sklejony w jeden długi "wiersz"), a perl wczytując takie dane dzieli je na osobne wiersze wg. znaku o kodzie 0. Nie byłoby to możliwe, gdyby nie opcja -0, która jest odpowiedzialna za podział danych wczytanych wg. znaku o kodzie 0. Dlatego perl, choćby nawet wczytał całość tekstu od razu, będzie traktował go jako zbiór wierszy, ponieważ podział na wiersze następuje przed przetwarzaniem reszty kodu (inaczej mówiąc, do skryptu trafiają już osobne, podzielone wiersze z początkowego strumienia danych). Opcja -e w obu przykładach, oczywiście, powoduje wykonanie skryptu umieszczonego w dalszej części wiersza poleceń. W przypadku drugim kod skryptu może być pusty, ponieważ wszystkie potrzebne operacje zostaną wykonane przez perla automatycznie.- Zapisz w pliku opowiadanie Stanisława Lema dostępne na stronie http://www.lem.pl/polish/opowiadania/opowiadania4.htm. Jeżeli zrobisz to prawidłowo, w pliku powinno znajdować się 21 wierszy (zachowane zostają akapity). Używając następnie opcji -a perla napisz program, który obliczy ile jest słów w najdłuższym akapicie.
Treść strony WWW można zaznaczyć myszą i następnie wkleić do pliku za pomocą polecenia cat > lem.txt i kliknięcia środkowym przyciskiem myszy lub poprzez naciśnięcie shift+insert na klawiaturze. Zależnie od tego, ile tekstu było zaznaczone, liczba wierszy w wynikowym pliku może mieścić się w granicach 21-50. Taka liczba wierszy jest ok. Inny sposób, to zapisanie strony na dysk za pomocą przeglądarki jako tekst. To zły sposób, gdyż akapity zostaną pocięte na osobne wiersze i w takim przypadku może ich być w pliku ponad 200! Gdy nie działa środkowy przycisk myszy (bo np. mysz go nie ma), można próbować nacisnąć jednocześnie przycisk lewy i prawy (może to działać jak naciśnięcie środkowego przycisku, tylko wtedy, gdy taka opcja została włączona). Jeżeli nie ma możliwości wykorzystania myszy, a terminal nie przyjmuje kombinacji Shift+Insert, to mamy wyjątkowo nieprzyjazną konfigurację... Można wtedy poradzić sobie tak: zaznaczamy cały tekst na stronie w przeglądarce za pomocą Ctrl+A, i następnie kopiujemy go do schowka za pomocą Ctrl+C. Uruchamiamy program np. kate (okienkowy edytor tekstowy) lub inny edytor, współdzielący schowek w którym właśnie zapamiętaliśmy tekst, i wklejamy treść opowiadania za pomocą Ctrl+V. Jest to tzw. windowsowy sposób. Plik zapisujemy np. jako lem.txt. Otrzymać wtedy możemy źródło danych, które zawiera od 30 do 50 wierszy (i to także jest w miarę ok). Mamy zatem źródło danych, które należy tak przetworzyć, aby obliczyć ile jest wyrazów w najdłuższym wierszu. Jest to bardzo proste zadanie, ponieważ istnieje mechanizm perla oparty na opcji -a, która automatycznie dzieli wiersz na części. Podział następuje na białych znakach, chyba że określimy inaczej. Zatem po podaniu opcji -a, każdy wiersz jest dzielony i jego fragmenty umieszczane są w tablicy @F. Oczywiście oryginalny wiersz jest nadal zachowywany w zmiennej domyślnej $_. Mając tablicę @F (inną dla każdego wiersza), wystarczy tylko określić jej długość (czyli liczbę elementów), a potem znaleźć największą wartość, aby wiedzieć, ile wyrazów ma najdłuższy akapit. Jedno z możliwych rozwiązań może mieć następującą postać:perl -lane '$a=($a<@F)?@F:$a;END{print $a}' lem.txtDziałanie tego prostego skryptu jest następujące: używamy opcji -l (wypisanie nowej linii po każdym print), -a (podział wiersza na części wg. znaków białych, dodatkowo zignorowane są spacje poprzedzające i kończące wiersz), -n (przetworzenie wszystkich wierszy), -e (wykonanie skryptu). W samym skrypcie używamy tak naprawdę dwóch zmiennych: $a, która pamięta aktualnie największą długość wiersza znalezioną do tej pory, oraz @F, która jest dla każdego wiersza tablicą z elementami pochodzącymi z jego podziału. Program działa tak, że dla każdego wiersza wykonywana jest operacja porównania aktualnej wielkości tablicy @F z największą do tej pory znalezioną wartością. Jeżeli okaże się, że słów jest więcej, niż znaleziono do tej pory, to ten wynik jest zapamiętywany, w przeciwnym wypadku następuje przypisanie zmiennej $a do zmiennej $a, co oczywiście nie zmienia jej wartości. Ten program stanowi przykład wyszukiwania wartości maksymalnej z ciągu nieuporządkowanych danych. Danymi w tym przypadku są długości tablicy @F, lub mówiąc bardziej w konwencji zadania: liczby słów w kolejnych wierszach. Gdyby komuś nie podobał się taki program, jego alternatywna wersja (nie jednolinijkowa), mogłaby mieć postać np. taką:#!/usr/bin/perl -w use strict; my $a = 0; while(<>){ my @F = split; if( $a < scalar @F ){ $a = scalar @F; } else{ $a = $a; } } print "$a\n";Ten program nie robi dokładnie tego samego, ale działa bardzo podobnie. Wynikiem jest liczba 357, co oznacza, że Lem potrafił napisać w jednym akapicie aż tyle wyrazów. Często też składały się one na niewiele zdań, gdyż długie, bardzo długie zdania u Lema to norma :) Prawie strumień świadomości :) Zachęcam do zapoznania się z literaturą jaka jest w dorobku tego znakomitego polskiego pisarza. To jednak zadanie pozaprogramowe :)- Korzystając z pliku z numerami IP oraz opcji autosplit wyświetl czwartą, ostatnią kolumnę numerów. Plik jest do pobrania tutaj (został on wygenerowany programikiem perla - jakim?). Jeżeli wykonasz wszystko prawidłowo, to w ciągu danych będzie tylko jedna cyfra 1 oraz dwie cyfry 3. Jak to sprawdzić?
Oto kolejne proste i przyjemne zadanie na używanie opcji -a, tym razem z wymuszeniem zmiany znaku podziału akapitów. Nasz strumień danych zawiera wiersze, które podzielić należy wg. kropki. Można to zrobić np. w taki sposób:perl -F'\.' -lane 'print $F[3]' ip.txtOtrzymamy wtedy listę liczb, które będą liczbami z ostatniej, czwartej kolumny liczb składających się na adresy ip zawarte w pliku. Warto zauważyć, że opcja -F zawiera tutaj dodatkowy argument, którym jest odpowiednio cytowana kropka ('\.'). Dzięki temu perl wie, że dzielić znaki ma według kropki, a nie według dowolnego znaku (kropka w wyrażeniach regularnych oznacza dowolny znak). Podział powoduje, że z numeru IP pozostają w tablicy @F cztery liczby, i czwartą z nich (czyli $F[3]) wypisujemy. Opcja -l powoduje, że dodajemy znak nowej linii po każdej instrukcji print, a działanie -a oraz -n umożliwia podział i przeiterowanie po wszystkich wierszach. Sprawdzenie czy w strumieniu liczb uzyskanych na wyjściu znajduje się rzeczywiście tylko jedna jedynka i dwie trójki można zrobić najbardziej trywialnie na świecie: dodając polecenie posortowania danych wynikowych, np. tak:perl -F'\.' -lane 'print $F[3]' ip.txt | sort -nrPolecenie sort ma tutaj posortować wszystkie numery za pomocą porównań liczbowych (tekstowe ustawią liczby w kolejności 1 10 11 2, itp) oraz w kolejności malejącej. Dlatego kolumna liczb zakończona zostanie przez:... 21 16 14 3 3 1... co naocznie stanowi dowód, że w serii danych znajdą się tylko dwie trójki i jedna jedynka. Tak! Nie chodziło o cyfry w liczbach, jak myśleli niektórzy. :)- Sprawdź działanie opcji -u, która morduje program i powoduje zrzut pamięci do pliku core. Jeżeli nie działa to polecenie, upewnij się, że ustawiłeś odpowiednie limity zrzutów pamięci za pomocą polecenia ulimit. Zwykle dla perla wystarczy ustawić limit wielkości na 10MB.
Aby wykonać to zadanie, należy wcześniej ustawić sobie limit na wielkość pliku core, co robi się za pomocą polecenia ulimit -f 10240 (na przykład). Następnie należy wykonać jakiś skrypt perla, np. perl -e 'print "BLA"' i dodać dodatkowo opcję -u. Efekt działania tej opcji będzie taki, jakby nasz program został zamordowany, z jednoczesnym zrzutem pamięci. Gdy limit został odpowiednio ustawiony, w katalogu w którym uruchomiono skrypt znaleźć będzie można plik core, w którym znajduje się zrzut pamięci całego procesu.- Wykorzystaj plik z numerami ip, który powinieneś mieć już pobrany. Używając opcji -i zamień w tym pliku wszystkie cyfry 2 na 8. Można to zrobić wykorzystując tzw. wyrażenie regularne, które zapisane jest następująco: $_ =~ /2/8/gms;. Oczywiście, dodać należy odpowiednie pozostałe elementy programu. Wykorzystując tę technikę w połączeniu z programem find można zamieniać zawartość całych drzew katalogów w systemie plików.
Opcja -i pozwala wykonać modyfikację pliku aktualnie przetwarzanego przez perla. Polega to na tym, że wszystko, co zostanie przez perla 'wypisane', trafi do nowej wersji pliku. Jeżeli nasz skrypt nie wypisze niczego, plik zostanie wyzerowany. W tym zadaniu należy taką modyfikację wykonać na przykładzie pliku ip.txt, używanego wcześniej. Polecenie, które robi taką modyfikację jest bardzo proste:perl -i -pe 's/2/8/g' ip.txtUżyć tutaj musimy opcji -p, aby zagwarantować, że każda linia z pliku zostanie przepisana do nowej wersji pliku (oczywiście niektóre linie z modyfikacją). Gdyby napisać po prostu perl -i -ne 's/2/8/g' to nasz plik zostałby obcięty. Trzeba dodać wypisanie wyników zmian, zatem postać skryptu np. taka: perl -i -ne 's/2/8/g;print' jest prawidłowa, i także spowoduje modyfikację. Generalnie za regułę należy przyjąć schemat przetwarzania taki, w którym perl nieformalnie wpisuje wszystkie wyprodukowane przez nas wyniki do pliku tymczasowego, a gdy program zakończy się, zamienia pliki - stary plik zostaje usunięty, a na jego miejscu pozostaje plik tymczasowy o tej samej nazwie. Jeżeli podamy do opcji -i argument tekstowy, to utworzona zostanie kopia zapasowa. Postać tego argumentu może zawierać gwiazdkę, która będzie podstawiona nazwą starego pliku użytego do zamiany, np. -i*.bak doda na końcu nazwy rozszerzenie .bak, natomiast -i 'old_*' doda przed każdą nazwą przyrostek old_. Gwiazdka może wystąpić wielokrotnie we wzorcu nazwy plików zapasowych, i będzie podstawiana przez nazwę aktualnie modyfikowanego pliku.- Wypróbuj działanie opcji -p na pliku z numerami ip. Dlaczego program perl -pne '' ip.txt działa? Jak możesz go przedstawić w normalny sposób, bez opcji -p?
Opcja -p tworzy wokół programu niejawną pętlę, której kod można porównać do bloku:while(<>){ # tutaj kod programu } continue{ print $_; }Każdy program jest w przypadku użycia opcji -p obudowany taką pętlą, zatem nawet gdy nic nie jest treścią programu, pętla może się prawidłowo wykonać. W tym przypadku efektem jej działania będzie po prostu wypisanie całego otrzymanego wejścia bez żadnych modyfikacji. Dodatkowo, stosowanie notacji w opcjach -pn jest nadmiarowe. Opcja -p implikuje opcję -n, która po prostu dodaje pętlę wokół programu (bez instrukcji print). Gdy występuje opcja -p, podawanie opcji -n jest zbędne. Gdyby natomiast program miał działać bez opcji -p i wypisywać wyniki tak samo jak po podaniu opcji -p, należałoby do programu dodać jawnie polecenie print $_.- Wykonaj program: perl -e 'print $a'. Wykonaj też program perl -w -e 'print $a' Widzisz różnicę?
Różnica polega na tym, że pierwsze uruchomienie perla następuje bez włączonego trybu ostrzeżeń, natomiast drugie już z tym trybem włączonym. Efekt jest widoczny w postaci komunikatu:Name "main::a" used only once: possible typo at -e line 1. Use of uninitialized value in print at -e line 1.Dostajemy dwa ostrzeżenia (nie są to błędy krytyczne, chociaż takie zachowanie można wymusić), pierwsze mówi o tym, że zmiennej $a użyliśmy tylko jeden raz (i że jest to możliwa literówka), drugie ostrzeżenie mówi o tym, że zmienna $a ma wartość niezdefiniowaną podczas próby jej wypisania w instrukcji print. Podczas pisania bardziej zaawansowanych programów tego typu komunikaty są nieocenione, gdyż zazwyczaj wartość niezdefiniowana jest pierwszym sygnałem jakiegoś błędu. Dlatego też należy unikać stylu programowania w którym wartość undef jest nośnikiem informacji (przykładowo, jeżeli jest undef, to wiemy, że coś ważnego i oczekiwanego nastąpiło). Taki styl programowania jest podatny na błędy w interpretacji znaczenia wartości niezdefiniowanej. Więcej na ten temat (oraz na temat stylu programowania) będzie w przyszłym semestrze.- Sprawdź działanie opcji -M na przykład ładując moduł MIME::Parser. Zmierz czas wykonania programu który nic nie robi, gdy ładowany jest ten moduł oraz bez ładowania. Przypomnienie: najkrótszy program, który nic nie robi, to perl -e 1. Dodaj do niego opcję ładowania bibliotek i mierząc czas wykonania za pomocą polecenia time upewnij się, że rzeczywiście jest różnica. Jeżeli czas ładowania pojedynczego modułu jest za krótki, załaduj więcej różnych modułów.
Uniwersytet Gdański - Instytut Informatyki - Strona domowa - Perl - ZadaniaNależało w tym przypadku wywołać perla z automatycznie ładowanymi modułami i programem pustym, oraz zmierzyć czas. Przykładowe polecenia, które realizowały takie zadanie, mogły wyglądać następująco (wyniki pomiarów także są przykładowe):time perl -MMIME::Parser -e 1 # czas 0.228s time perl -MXML::Parser -e 1 # czas 0.053s time perl -MTime::HiRes -e 1 # czas 0.023s time perl -MText::Wrap -e 1 # czas 0.024s time perl -MDBI -e 1 # czas 0.053s time perl -MXML::Parser -MData::Dumper -MList::Util -MMIME::Entity -MTime::HiRes -e 1 # czas 0.404s[c] Piotr Arłukowicz, materiały z tej strony udostępnione są na licencji GNU. - Wykonaj polecenie find . -print0 aby się przekonać co będzie jego wynikiem. Napisz następnie filtr perlowy, który spowoduje wyświetlenie wszystkich nazw plików w postaci listy jednokolumnowej. Jest to zadanie na użycie opcji uruchomieniowej perla -0 (minus zero). Oraz paru innych :)