Moduł Proc::Fork
Uniwersytet Gdański - Instytut Matematyki - Zakład Informatyki - Strona domowaSpis treści
Obsługa modułu Proc::Fork
Co to jest
Proces - to jedno z najbardziej podstawowych pojęć w informatyce. Jest to po prostu egzemplarz wykonywanego programu. Należy odróżnić jednak proces od wątku - każdy proces posiada własną przestrzeń adresową, natomiast wątki posiadają wspólną sekcję danych. Każdemu procesowi przydzielone zostają zasoby, takie jak procesor, pamięć, dostęp do urządzeń wejścia-wyjścia, pliki. Każdy proces posiada tzw. "rodzica". W ten sposób tworzy się swego rodzaju drzewo procesów. Proces może mieć również procesy potomne. Za zarządzanie procesami odpowiada jądro systemu operacyjnego.
Proc::Fork to moduł autorstwa Aristotle Pagaltzis'a. Moduł, który przedstawię pozwala nam na podział programu na osobne procesy.
Download
- Pakiet możemy pobrać z CPANu
Instalacja w systemie UNIX'owym
Po rozpakowaniu modułu wydajemy polecenie
perl Makefile.PL
make
make install
Sprawdzamy, czy został on pomyślnie zainstalowany, pisząc jednolinijkowca
perl -e 'use Proc::Fork'
Pomyślne wykonanie programu (żadnych komunikatów) daje nadzieję, że moduł został zainstalowany poprawnie i będzie działał. Jeżeli wszystko poszło zgodnie z planem to możemy już korzystać z możliwości naszego nowego modułu.
Opis
Używanie modułu jest naprawdę intuicyjne. Możemy pisać programy korzystające z procesów, używając bloków, które w prosty sposób odpowiadają za wykonanie kodu w odpowiednim procesie. Kod dla procesu rodzicielskiego, potomnego, uchwytu wznowienia oraz uchwytu dla błędów jest zgrupowany w bloki procesu. Bloki te mogą pojawić się w dowolnej kolejności, lecz nie możemy umieszczać żadnych danych pomiędzy nimi. Obowiązkowy jest również przecinek na końcu bloku. Nie trzeba umieszczać wszystkich czterech bloków. Jeżeli zostanie pominięty blok rodzicielski lub potomny, to odpowiedni proces zacznie wykonywanie po ostatnim bloku, możemy to przedstawić tak:
# Proces potomny
child {
coś do zrobienia
};
# Proces rodzicielski rozpocznie wykonywanie od tego momentu
coś do zrobienia
Interfejs
- child
- Ta funkcja wykonuje przekazany do niej kod, jeżeli będzie to proces potomny
child { ... } - parent
- Ta funkcja wykonuje przekazany do niej kod, jeżeli będzie to proces rodzicielski. Umieszcza PID procesu potomnego.
parent { ... } - retry
- Ta funkcja wykonuje przekazany do niej kod, jeżeli wystąpił błąd lub proces zwrócił undef. Jeżeli kod zwróci true, podejmowany jest kolejny proces. Jeżeli ten blok nie jest użyty, nie zostaną podjęte żadne wznowienia i niepowodzenie procesu doprowadzi do błędu bloku do którego się odwołuje proces.
retry { ... } - error
- Ta funkcja wykonuje przekazany do niej kod, jeżeli wystąpił błąd, proces zwrócił undef i blok wznowienia (retry) zwrócił false. Jeżeli blok błedu nie jest użyty, wszelkie błędy podniosą wyjątek używając die.
error { ... } - child
- parent
- retry
- error
- Macierzysta strona dokumentacji do modułu http://search.cpan.org/~aristotle/Proc-Fork-0.4/lib/Proc/Fork.pm
Eksport
Pakiet ten eksportuje domyślnie następujące symbole
Przykład
Pierwszy program będzie polegał na wypisaniu tekstu na ekran (przekazanego przez proces potomny) przez proces rodzicielski. Kod posiada komentarz, więc powinien być zrozumiały dla każdego.
use strict;
use IO::Pipe;
use Proc::Fork;
#Rura
my $p = new IO::Pipe;
#Proces rodzicielski
parent {
print "Jestem w parent\n";
#PID potomnego
my $child = shift;
#Czytamy z rury
$p->reader;
#Wypisujemy zawartość jeżeli coś się pojawiło
print while ( <$p> );
waitpid $child,0;
}
#Proces potomny
child {
print "Jestem w child\n";
#Piszemy do rury
$p->writer;
print $p "Piszemy ";
print $p "Coś\n";
};
Oto co otrzymamy po wykonaniu programu
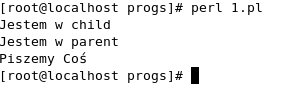
Drugi program pokazuje komunikację z wieloma procesami potomnymi. Za każdym razem angażowane są inne procesy potomne.
use strict;
use Proc::Fork;
use IO::Pipe;
my $num_children = 5; #Ilość utworzonych procesów
my @children; #Tablica w której przechowujemy połączenia do procesów
#Dla każdego procesu jest tworzona rura do komunikacji
for my $num ( 1 .. $num_children ) {
#Utworzenie rury do połączenia
my $pipe = new IO::Pipe;
# Proces potomny wypisuje otrzymane dane
child {
$pipe->reader;
my $data;
while ( $data = <$pipe> ) {
chomp $data;
print STDERR "child $num: [$data]\n";
}
exit;
};
#Proces rodzicielski przechowuje połączenia do każdego procesu w tablicy @children
$pipe->writer;
push @children, $pipe;
}
# Wysyłamy dane do losowych procesów
for ( 1 .. 20 ) {
#Losujemy numer procesu
my $num = int rand $num_children;
#Połączenie z odpowiednim procesem
my $child = $children[$num];
#Wysyłamy komunikat
print $child "Cześć to ja.\n";
}
Pierwsze przykładowe wykonanie programu
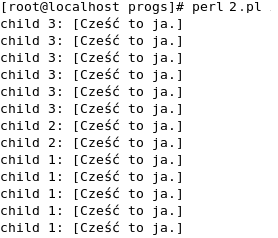
Drugie przykładowe wykonanie programu
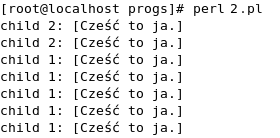
Dodatkowe informacje
Za pomocą tego modułu możemy tworzyć bardzo ciekawe programy, począwszy od podziału zadań w programie na poszczególne procesy, do wszelkiego rodzajów 'demonów' i usług sieciowych. Po dodatkowe informacje odsyłam na stronę z dokumenacją modułu.
Autor opracowania
Adrian Sielski
Email: adrian.sielski@gmail.com