Moduł Data::Dumper
Uniwersytet Gdański - Instytut Matematyki - Zakład Informatyki - Strona domowaObsługa modułu Data::Dumper
Co to jest
Moduł Data::Dumper to powszechnie wykorzystywane narzędzie do wyświetlania zawartości zmiennych złożonych oraz do serializacji danych. W skrócie, można za jego pomocą wyświetlić zawartość tablicy tablic albo innych wielopoziomowych, skomplikowanych struktur danych. Moduł ten nie wyświetla zawartości odwołań do kodu, ani zawartości plików. Nadaje się natomiast do wyświetlenia zawartości zmiennych
Wyświetlanie danych za pomocą modułu Data::Dumper w najprostszym zastosowaniu polega na wypisaniu tego, co zwróci funkcja Dumper (domyślnie importowana przez Data::Dumper do pakietu bieżącego). Zawartość tej funkcji to najczęściej napis, który zawiera informację o zmiennej i jej zawartości. Zmienne, jeżeli nie określi się tego inaczej, są przez moduł wypisywane jako nazwy $VAR1, $VAR2, itd. Wszystkie powinny być referencjami, chociaż możliwe jest też używanie modułu do wypisywania zmiennych nie będących referencjami.
Wyświetlanie tablicy
Poniższy przykład przedstawia sposób wyświetlenia zawartości zmiennej tablicowej.
use Data::Dumper;
my @tablica = ( 1 .. 10 );
print Dumper \@tablica;
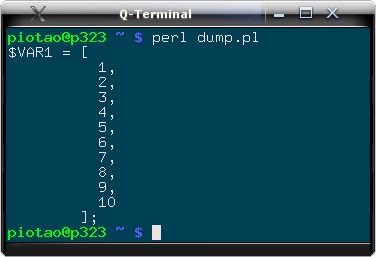 |
Rys. 1. Zrzut zawartości tablicy @tablica uzyskany za pomocą modułu Data::Dumper. Kod programu był bardzo prosty:
use Data::Dumper;
@tablica = (1..10);
print Dumper \@tablica;
|
Wyświetlenie hasza
Używając modułu Data::Dumper, możemy wyświetlać także tablice asocjacyjne, zwane potocznie haszami.
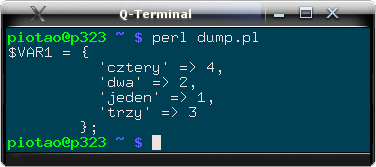
Rys. 2. Zrzut zawartości tablicy asocjacyjnej (hasza) %hash uzyskany za pomocą modułu Data::Dumper. Kod programu był prosty:
use Data::Dumper;
%hash = ( jeden => 1, dwa => 2, trzy => 3, cztery => 4 );
print Dumper \%hash;
|
Dane zagnieżdżone
Wyświetlanie danych zagnieżdżonych dokonuje się dokładnie tak samo, jedyne, co trzeba podać modułowi do wyświetlania, to referencja do zmiennej. Oto przykład na wyświetlenie zawartości tablicy zawierającaej pola różnego typu.
use Data::Dumper;
$dane = [ # uwaga - tworzymy tablice anonimowa - [...]
1, # zwykle dane skalarne
{ # to bedzie anonimowy hasz, bo {...}
jeden => 2, # klucz=>wartosc hasza
},
\-3.14, # referencja do stalej (do ujemnej liczby rzeczywistej
];
print Dumper $dane; # ... i tyle. :)
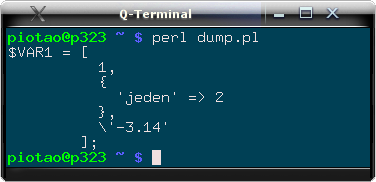 |
Rys. 3. Zrzut wartości wskazywanej przez referencję do tablicy, zawierającej trzy elementy, z których jeden jest anonimowym haszem. W przypadku wielopoziomych struktur każdy kolejny poziom zagłębienia jest wypisywany z odpowiednim wcięciem.
Dodatkowo, widać, że elementy tablicy zachowały kolejność. W poprzednim przykładzie (patrz rys. 2) elementy hasza nie zachowały kolejności przy ich wypisywaniu.
|
Funkcje zaaawansowane
Nazywanie zmiennych
Moduł Data::Dumper oferuje także oprócz prostego, proceduralnego podejścia także możliwość nazwania zmiennych wyprowadzanych do wynikowego tekstu. Aby wykorzystać tę funkcję, należy do funkcji Dumper przekazać dwie referencje do tablic. W pierwszej z nich muszą znaleźć się zmienne, w drugiej - ich nazwy podane jako napisy. Zobacz na przykład poniżej:
use Data::Dumper;
$foo = "bla";
$bar = [1,2,3];
print Data::Dumper->Dump( [$foo, $bar], ['foo','bar'] );
Inne podejście do tego samego zadania zapewnia metoda obiektowa, którą moduł udostępnia:
use Data::Dumper;
$foo = "bla";
$bar = [1,2,3];
$dump = Data::Dumper->new([$foo,$bar], [qw(foo bar)]);
#...
#... dalszy ciąg programu i nagle:
print $dump->Dump;
Tego typu podejście jest najbardziej zalecane w większych programach, które na żądanie lub podczas debugowania mają wypisywać stan swoich zmiennych.
Zmienne konfiguracyjne
Istnieje pewna grupa zmiennych, która zmienia domyślne działanie funkcji Dumper i w konsekwencji postać wynikową generowanego kodu perla zawierającego treść danych. Używanie tych zmiennych łamie pewne ogólnie przyjęte konwencje programowania, ponieważ dopuszcza zmianę wewnętrznego stanu klasy Dumper, ale można na to przymknąć oko, ponieważ są metody pozwalające uniknąć problemów (np. lokalizowanie zmiennych perla).
Poniżej zamieszczam krótkie omówienie niektórych zmiennych, które mogą się przydać w codziennej pracy programisty perlowego.
- $Data::Dumper::Indent lub $dump->Indent( nowa_wartość )
- Jest to zmienna kontrolująca styl wcięć, jakie tworzone są dla danych zorganizowanych hierarchicznie. Wartość ta może być ustawiona na 0, 1, 2 lub 3. Styl 0 powoduje tworzenie tekstu bez żadnych nowych linii wstawiananych dla zwiększenia czytelności, bez wcięć i bez spacji pomiędzy elementami list. Jest to najbardziej kompaktowa forma możliwa do późniejszego przeparsowania przez perla. Styl 1 wyprowadza czytelną postać danych z nowymi liniami bez żadnego wymyślnego wcinania od lewej (każdy poziom struktury jest po prostu wcinany za pomocą ustalonej liczby spacji). Styl 2, domyślny, wyprowadza bardzo czytelną formę danych, w których jest uwzględniana długość kluczy w haszach i wcięcia ustawiane są na odpowiednią głębokość. Styl trzeci robi to samo co drugi, a ponadto opisuje elementy tablic ich indeksami (umieszczanymi w osobnych wierszach jako komentarz).
- $Data::Dumper::Purity albo $dump->Purity( wartość )
- Wynik generowany przez moduł Dumper może być ponownie przetworzony przez perla w celu odtworzenia takich samych danych, jakie wypisano. Wystarczy wykonać eval na tekście, który jest wynikiem z metody Dump lub funkcji Dumper. Jednak w takim przypadku należy odpowiednio potraktować referencje wielokrotne do tych samych danych. Zmienna ta kontroluje stopień w jakim wynik może być obliczany/wykonany przez eval, aby odtworzyć daną strukturę z jej wewnętrznymi referencjami. Ustawienie tej zmiennej na 1 dodaje dodatkowe wyrażenia perla, pozwalające bezbłędnie wykonać i odtworzyć całą złożoność struktury z zagnieżdżonymi odwołaniami. Wartość domyślna to 0.
- $Data::Dumper::Pad lub $dump->Pad( wartość )
- Zmienna określa napis, jaki ma się pojawić przed każdą nową linią wyniku. Standardowo jest to pusty napis.
- $Data::Dumper::Varname lub $dump->Varname( wartość )
- Zawiera napis, który stanie się prefiksem każdej nazwy zmiennej wyprowadzanej w wyniku. Domyślnie jest to napis "VAR".
- $Data::Dumper::Useqq lub $dump->Useqq( wartość )
- Gdy ta zmienna jest ustawiona, włączone zostaje użycie podwójnego cytowania dla wartości tekstowych. Białe znaki inne niż spacja reprezentowane będą przez nową linię "\n", tabulator "\t" lub powrót karetki "\r", "niebezpieczne", lub nietypowe znaki będą poprzedzone znakiem ukośnika odwrotnego "\", a niedrukowalne znaki będą wyprowadzone jako całkowite liczby ósemkowe. Działanie funkcji Dump/Dumper jest wolniejsze, gdy ta zmienna jest ustawiona, dlatego domyślnie ma ona wartość 0.
- $Data::Dumper::Maxdepth oraz $dump->Maxdepth( wartość )
- Ta zmienna może być ustawiona na dodatnią wartość całkowitą, która określa głębokość, powyżej której zawartość danych nie zostanie wypisana w pełnej postaci. Nie ma efektu, gdy ustawiono zmienną "Purity". Standardowo ma wartość 0, co oznacza brak maksymalnej głębokości skanowania. Ustawienie zmiennej na 1 powoduje produkowanie tylko pierwszego poziomu struktury złożonej, kolejne, głębsze referencje są przestawiane w typowy sposób.
Pozostałe szczegóły są opisane w dokumentacji modułu, można je wyświetlić wpisując polecenie perldoc Data::Dumper lub man Data::Dumper, lub np. tutaj: http://perldoc.perl.org/Data/Dumper.html.