Wyjściowka nr. 8 :C
Uniwersytet Gdański - Instytut Matematyki - Zakład Informatyki - Strona domowaPytania i zadania
Odpowiedz na zebrane poniżej zadania.
Zadania przygotowane są w dwóch zestawach. Można rozwiązać tylko jeden zestaw i tylko jeden jest liczony przy podsumowaniu wyników. Pierwszy zestaw to programowe koło z dziedziczenia obiektów i związanej z tym tematyki. Drugi zestaw to koło w pewien sposób powtórzeniowe, w którym znajdują się względnie proste zadania z całego przerobionego materiału, wymagające jednak nieco szerszej wiedzy. Wybór należy zawsze do ciebie: rozwiąż zadania z jednego bądź drugiego zestawu i zdobądź punkty uprawniające do zaliczenia!
Odpowiedzi wyślij mailem pod tyt. [kolo 8] grupaN Imię Nazwisko (N-numer grupy)
Przestrzegaj limitu czasu pisania - max 30 minut. Max punktów do zdobycia: 7. Powodzenia!
Zadania dla grupy 1
Start: 2007-05-16 15:00, czas: 30 minut czasu delty.-
Zestaw A: zadania standardowe (kursowe)
- (2p) Wyjaśnij swoimi słowami, na czym polega dziedziczenie i pokaż jakś prosty, poglądowy przykład.
Dziedziczenie jest nazwą pewnej techniki programowania obiektowego, w której klasy obiektowe są od siebie zależne i wykorzystują swój kod. Hierarchia zależności klas jest jednokierunkowa (zależności między klasami można opisać jako liniowe lub drzewiaste), i w wyniku jej ustanowienia pewne cechy klas rodzicielskich mogą być używane w klasach potomnych. Ponieważ mowa tu o hierarchii, rodzicach, potomkach i dzieleniu się wspólnymi cechami, naturalne staje się wprowadzenie pojęcia dziedziczenia, które określa że cechy rodzica (wyrażane przez np. metody obiektowe lub inne właściwości) są także dostępne w klasie potomnej. W perlu możliwe jest zrealizowanie dziedziczenia metod (bez specjalnych zabiegów nie daje się dziedziczyć innych elementów składowych). Dziedziczenie metod polega na tym, że po określeniu związku między dwiema klasami, jedna z nich staje się klasą rodzicielską, a druga klasą potomną. W klasie potomnej dostępne są wtedy wszystkie metody z klasy rodzicielskiej (a odwrotnie nie). Relacja taka nie może być cykliczna, a w perlu określa się przez słowa kluczowe use base LISTA, gdzie LISTA zawiera listę klas rodzicielskich, bowiem możliwe jest dziedziczenie poziome po wielu przodkach. Oto przykłady:
package Dziecko; use base qw(Życie Ssak Kregowiec Czlowiek);Klasa Dziecko dziedziczy po wielu klasach typowe dla nich cechy, zatem można się spodziewać, że będzie w niej dostępna metoda np. żyj z klasy Życie, ssij z klasy Ssak, itp. Inna forma dziedziczenia to dziedziczenie proste (pojedyncze) wyrażane przez łańcuch klas ustawionych w szereg od praprzodka:package Życie; ... 1; package Ssak; use base 'Życie'; ... 1; package Kregowiec; use base 'Ssak'; ... 1; package Czlowiek; use base 'Kregowiec'; ... 1; package Dziecko; use base 'Czlowiek'; ... 1;W przypadku takiego kodu także dostępne są wszystkie typowe metody z klas rodzicielskich w klasie Dziecko, ale są pewne różnice. Główna różnica to fakt, że dziedziczenie liniowe to dziedziczenie inkluzywne, to znaczy, metody najbardziej pierwotne, pochodzące od praprzodka są dziedziczone przez każdą klasę, a w przypadku dziedziczenia poziomego po wielu przodkach równocześnie tak nie musi być, ponieważ np. klasa Ssak może nic nie wiedzieć o metodzie żyj z klasy Życie. W praktyce spotyka się oba systemy dziedziczenia, chociaż dziedziczenie wielokrotne po wielu przodkach (w poziomie) jest uznawane za trudniejsze do zarządzania i ogarnięcia, ponieważ stanowi ono połączenie być może całkiem różnych hierarchii klas, niezależnie od siebie istniejących. - (1p) Czym różni się zapis our @ISA = qw(Moduł); od zapisu use base qw(Moduł);?
Podstawową różnicą jest to, że pierwszy z zapisów wykona się w trakcie wykonania programu (zwykła instrukcja przypisania), natomiast druga wersja wykona się na etapie kompilacji. Dodatkowo efektem drugiej instrukcji jest automatycznie załadowanie odpowiednich, wymienionych w liście modułów.
- (2p) Na podstawie dowolnej hierarchii dwóch klas (być może wymyślonych) wyjaśnij, co to jest metoda wirtualna.
Metody wirtualne zwykle definiuje się jako metody puste, silnie związane z abstrakcją (lub wręcz abstrakcyjne - zależnie od języka) i napisane tylko po to, aby je pokryć w klasie potomnej. W perlu nie ma czegoś takiego jak abstrakcja wymuszona składniowo - to znaczy - można napisać metody, które nie robią nic, ewentualnie wywołują błąd, ale tylko na poziomie obsługi zapewnianej przez programistę, nie przez język. Zatem wirtualność w perlu nie przypomina w ogóle tej znanej np. z C++. Nie ma także zjawiska wirtualności wynikającego z zapisu np. klasapotomna = new klasarodzicielska, ponieważ takie przypisanie w perlu jest w sumie możliwe, ale nie zadziała zgodnie z oczekiwaniami (typy danych na takim poziomie w perlu nie istnieją, aby możliwe było wołanie metod klasy potomnej z obiektu utworzonego jako typ rodzicielski, co możliwe jest dla metod wirtualnych). Wirtualność w perlu jest trochę wirtualna :) Wracając do konkretów, istnieje pewna cecha dziedziczenia, w której objawia się wirtualność metod. Aby zaprezentować to zjawisko, wystarczą dwie klasy, z których pierwsza implementuje metodę A i B, a druga - jako potomna, pokrywa tylko metodę B swoją własną wersją. Najlepiej zobaczyć to na obrazku:
package KlasaBazowa; sub A {... $self->B(); ...} # zauważ - wywołujemy metodę B z klasy KlasaBazowa! sub B {...}package KlasaPochodna; use base 'KlasaBazowa'; sub B {...}Załóżmy teraz, że mamy instancję klasy pochodnej daną jako obiekt o nazwie np. $poch. Jeżeli wykonamy metodę $poch->A();, to pierwsze co zauważamy jest fakt, że nie ma w klasie pochodnej implementacji tej metody, zatem wywoła się metoda dziedziczona. Metoda ta, wywoływana na poziomie klasy bazowej, wykona swój kod, wywołując jednocześnie metodę B. I tu pojawia się subtelne zjawisko wirtualności. Metoda A, wywoływana w klasie KlasaBazowa, normalnie wywołałaby metodę B z tej samej klasy. Jednakże w przypadku, gdy mamy klasę potomną, wywołanie nastąpi w taki sposób, że wykonana zostanie metoda B z klasy pochodnej, a nie bazowej, mimo, że metoda w klasie bazowej jest na tym samym poziomie. Jeżeli jest to trudno zrozumieć, to nie dziwię się. A jeżeli łatwo - cóż, w takim razie perl jest prostym językiem :) Oczywiście to działanie jest oczywiste, jeżeli głębiej się nad nim zastanowić. :) - (2p) Pytanie dowolne dotyczące obiektów w perlu. Uwaga: należy prawidłowo i jednoznacznie zadać sobie pytanie i poprawnie na nie odpowiedzieć. Nie wystarczy wyłącznie "zacytować" kodu (nie będę się domyślał ocb), i nie wystarczy zażądać czegoś w stylu "napisz konstruktor" (chyba że będzie to rzeczywiście coś ciekawego) :P Zestaw B: zadania powtórzeniowe (z całości):
- (2p) W jaki sposób uzyskać jedną listę wszystkich kluczy z wszystkich anonimowych haszy, umieszczonych w referencji do anonimowej tablicy? Zaproponuj przynajmniej jeden sposób.
To zadanie było bardzo proste. Oto mamy strukturę danych:
$dane = [ { a=>1, b=>2, }, { c=>3, d=>4, }, #... ];i trzeba wyjąć z niej wszystkie klucze. Można to zrobić np. w taki sposób:@klucze = map{ keys %$_ } @$dane;Naprawdę jest to aż tak proste. Szkoda, że nikt nie wymyślił takiego rozwiązania, za to widziałem jakieś obszerne konstrukcje i różne cuda... - (2p) Zaproponuj wyrażenie regularne, które dopasowuje się do dowolnego napisu typu href="http:" (lub location="http:", albo action="http:", ogólnie cokolwiek="http:") i przechwyci część napisu podkreśloną (to znaczy litery http), natomiast nie dopasuje się do napisu src="http:".
Kolejne bardzo proste zadanie, i co więcej - powinno być już doskonale proste... oto rozwiązanie:
/(?<!src)="(http):"/I tyle. Aby rzeczywiście uzyskać napis http w zmiennej, należy wykonać przypisanie w stylu $zmienna = $1;:if( /(?<!src)="(http):"/ ){ $zmienna = $1; }Wyrażenie to nie jest odporne na napisy dłuższe, np. dopasuje się także imgsrc i inne. Dlatego można dodać jeszcze granicę słowa:/(?<!\bsrc)="(http):"/ - (2p) Zaproponuj programik, który działając na zasadzie filtra wczyta strumień liczb oddzielonych białymi znakami i wypisze je jako liczby rzeczywiste na polach o szerokości 12, z precyzją 5, po 6 liczb w wierszu. Pokazuje to przykład: plik dane zawiera jakieś kolumny liczb. Twój program ma je po prostu wczytać i wypisać w innej postaci:
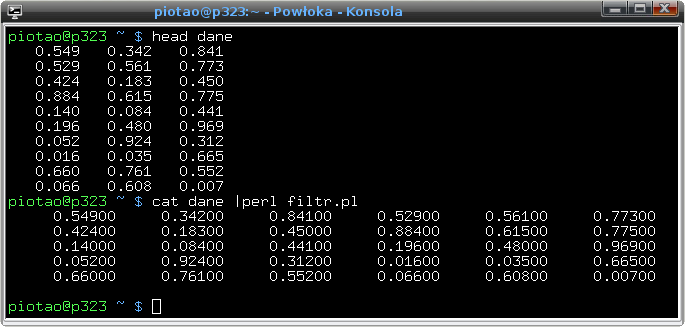
Efekt działania programu, który należy napisać.I jeszcze jedno super proste zadanie, które zresztą w podobnej formie pojawiło się już kiedyś wcześniej. Rozwiązanie polega na tym, aby wczytywać liczby, zrobić z nich jednolity strumień danych a następnie wypisywać go co któryś raz z nową linią, w ustalonym formacie. I to wszystko. Aby uzyskać strumień liczb, możemy na początek skrobnąć króciótki kod w stylu jednolinijkowca:perl -e 'print rand," " for 1..1e2'W ten sposób dostajemy 100 liczb losowych wypisanych jedna po drugiej w terminalu. Inny sposób:perl -le 'print rand for 1..1e2'wypisze liczby w słupku, po jednej w każdym wierszu. Tak czy inaczej, mamy strumień liczb (można też podać je z klawiatury - ich źródło jest obojętne). Następnie nasze źródło danych podpinamy pod program do formatowania strumienia, np. za pomocą rury (|). W ten sposób tworzymy polecenie strumieniowe: źródło | cel, w typowy sposób i robione to było wiele razy wcześniej, na początku roku :) Program, który układa liczby w wymagany w zadaniu sposób jest bardzo prosty, i może wyglądać np. tak:perl -ne 'push @a,split;END{ for(@a){printf "%12.5f",$_; print "\n" if !(++$a % 6)}}'Kod ten działa tak, że na początku wczytywane są wiersze, a każdy z nich dzielony jest przez split i od razu wszystkie elementy wrzucane są do tablicy @a. Działanie split bez żadnych parametrów jest magiczne - ignorowane są wszystkie białe znaki i o to chodzi! :) Następnie w bloku END wypisywane są wszystkie liczby z @a (za pomocą trywialnego for). Wypisywana jest liczba zgodnie z formatem "%12.5f", a dodatkowo, tylko jeżeli zmienna $a dzieli się przez 6 (co sprawdzamy za pomocą modulo - %) dodajemy do wyników znak nowego wiersza. Zmienna $a spełnia tu rolę licznika wypisywanych liczb - i co szósta z nich jest dopełniania nowym wierszem. Można było ten program rozwinąć do pełnej postaci skryptu, ale sam sens działania pozostawał taki sam i generalnie było kilka osób, które to zrobiły. :) - (1p) Zadanie dowolne, dotyczące perla. Uwaga: powinno ono być dostatecznie przemyślane i na odpowiednim poziomie :)
Zadania dla grupy 2
Start: 2007-05-17 16:30, czas: 30 minut czasu delty.-
Zestaw A: zadania standardowe (kursowe)
- (2p) Wyjaśnij swoimi słowami, do czego służy klasa UNIVERSAL.
Klasa UNIVERSAL to przodek wszsystkich klas. Przez perla jest traktowana trochę jak pseudoklasa, ponieważ jest ładowana automatycznie do każdego perlowego programu. Udostępnia metody can, isa oraz VERSION, importowane domyślnie do każdego pakietu przez moduł Exporter (można to sprawdzić oglądając kod pakietu UNIVERSAL.pm). Klasa ta służy w programach jako miejsce do definiowania globalnych zachowań lub do przechowywania globalnych danych bez udziału narzędzi do eksportu. Nie jest zalecane pisanie modułów korzystających z tej klasy, ponieważ każda zmiana w niej staje się widoczna wszędzie. Można jednak za jej pomocą "rozgłaszać" i udostępniać pewne metody lub mechanizmy singletonowe lub związane z obsługą kodu.
- (1p) W jaki sposób w perlu realizuje się dziedziczenie po wielu przodkach? Podaj oczywiście jakiś sensowny przykład.
Dziedziczenie można wykonać na dwa sposoby: pojedynczo, lub za pomocą wielodziedziczenia. Szczegóły są opisane w odpowiedzi do zadania 1 na kole 6 dla grupy 1, zestawu A, dostępnej tutaj.
- (2p) Wyjaśnij, w jaki sposób sprawdzić, czy dana zmienna skalarna należy do klasy Stupid oraz jak upewnić się, że klasa ta implementuje metodę cure.
W zadaniu chodzi o sprawdzenie, czy zmienna dana jako skalar jest instancją klasy Stupid, a nie czy w klasie Stupid zdefiniowano zmienną skalarną. Sprawdzenie skalara na okoliczność, czy jest obiektem robi się za pomocą operatora ref:
$nazwa_klasy = ref $zmienna;Jeżeli mieliśmy do czynienia z instancją obiektu, wyłuskamy z niej nazwę klasy. Jeżeli nie jest to klasa Stupid, możemy sprawdzić, czy w hierarchii klas istnieje dziedziczenie po tej klasie, za pomocą metody isa dziedziczonej wprost z UNIVERSAL:if( $zmienna->isa('Stupid') ){ ... }W dalszej kolejności możemy sprawdzić, czy klasa $nazwa_klasy, której instancję mamy w zmiennej $zmienna, implementuje metodę cure. Robimy to poprzez użycie metody can dziedziczonej także z klasy UNIVERSAL:if( $zmienna->can('cure') ){ .... }I to wszystko. Oczywiście niektórym osobom to nie wystarczyło, i pisały dodatkowo, jakie będą wyniki działania wspomnianych metod w różnych przypadkach. - (2p) Pytanie dowolne dotyczące obiektów w perlu. Uwaga: należy prawidłowo i jednoznacznie zadać sobie pytanie i poprawnie na nie odpowiedzieć. Nie wystarczy wyłącznie "zacytować" kodu (nie będę się domyślał ocb), i nie wystarczy zażądać czegoś w stylu "napisz konstruktor" (chyba że będzie to rzeczywiście coś ciekawego) :P Zestaw B: zadania powtórzeniowe (z całości):
- (2p) Zaproponuj przynajmniej jeden sposób na sortowanie nazw plików wczytanych z twojego domowego katalogu według rozmiaru plików za pomocą transformacji Schwartza.
Transformacja Schwartza jest operacją, która kilkukrotnie już się pojawiła (np. tutaj). Tym bardziej wykazać można się było finezyjnym jej zastosowaniem. I jak życie pokazało, zaledwie nieliczne osoby, posiłkując się w dodatku googlem, w haniebny sposób skleiło te marne parę linijek, aby uzyskać mniej lub bardziej sprawny kod :) W każdym razie, w zadaniu chodzi o to, aby ustawić nazwy plików w kolejności określonej przez rozmiary plików. Pragmatyczne podejście zakłada, że listę plików już mamy. Można zrobić ją wczytując np. wynik działania polecenia ls -1 lub użyć modułu File::Find. Oto jak można zrobić listę plików:
my @lista = `ls -1a`; chomp @lista; # plik z bieżącego (i tylko) katalogulub:use File::Find; my @lista; find( sub{ push @lista, $File::Find::name if -f $File::Find::name or -d $File::Find::name }, '.' );Lista plików to lista wszystkich plików i katalogów z podanej ścieżki. Nie wiem czemu, ale ten drugi rodzaj rozwiązania bardziej mi się podoba (chociaż nie miało to wpływu na wyniki koła). Tak czy inaczej, posiadając już listę plików należy wykonać ich sortowanie. Typowe podejście do zwykłego sortowania wygląda tak:@lista = sort { $a <=> $b } @lista;co oczywiście jest już znane. Gdyby tablica była dana przez referencję, kod wyglądałby inaczej. W przypadku Transformacji Schwartza tablica jest normalna, natomiast referencjami są jej elementy. Oznacza to, że mamy tablicę, której elementami są inne tablice (dane właśnie jako referencje) i elementy tych pod-tablic porównujemy. Ale od początku:
1. Tablicę nazw plików przetwarzamy na tablicę referencji. Każda referencja wskazuje na podtablicę z nazwą pliku i jego wielkością.
2. Sortujemy tablicę referencji, używając wielkości plików.
3. Tworzymy ponownie tablicę nazw plików korzystając z tablicy przestawionych (posortowanych) referencji.
W praktyce wygląda to tak:@lista = map{ [ $_, -s $_ ] } @lista; @lista = sort{ $a->[1] <=> $b->[1] } @lista; @lista = map{ $_->[0] } @lista;To jest właśnie Transformacja Schwartza. W zwykłych warunkach wszystkie te wiersze zapisuje się razem, tworząc jedną, dość elegancką i "zakręconą" konstrukcję:@lista = map{ $_->[0] } sort{ $a->[1] <=> $b->[1] } map{ [ $_, -s $_ ] } @lista;Dodatkowe wyjaśnienia i informacje na temat tej transformacji znajdziesz w zadaniu 2 z zestawu poświęconego strukturom wielowymiarowym. - (2p) Wyjaśnij na czym polega zachłanna alternacja (podpowiedź: dotyczy to wyrażeń regularnych).
Alternacja jest to inaczej "przeskakiwanie", "przebieranie" i w mechanizmie wyrażeń regularnych perla pojawia się wszędzie tam, gdzie dochodzi do sprawdzania wielu możliwości danych w postaci jawnie wpisanej alternatywy. Alternatywa to inaczej wybór z wielu, zapisywany za pomocą pionowej kreski:
/a|b|c|d/Maszyna wyrażeń regularnych jest gorliwa i zachłanna, ale w przypadku alternacji gorliwość wygrywa nad zachłannością. Oznacza to, że z listy dopasowań wybrane będzie zawsze pierwsze pasujące, a nie najlepsze pasujące. Przykładowo słowo końkurs dopasowane do wyrażenia /(koń|końkurs)/ będzie zawierało w przechwyconym dopasowaniu ($1) jedynie słowo koń, chociaż "bardziej" pasuje całe słowo końkurs. Gdyby alternacja była zachłanna, sprawdzane byłyby wszystkie możliwe dopasowania, i wybierano by (jak można przypuszczać) najlepsze. Warto też dodać, że analiza alternatyw następuje od lewej do prawej strony wyrażenia, zatem odpowiednio ustawiając elementy można sterować przebiegiem dopasowania i podpowiedzieć mechanizmowi dopasowującemu, które alternatywy są "lepsze" (te bardziej z lewej). - (2p) W jaki sposób wykonać pełną kopię zmiennej danej przez referencję? Zaproponuj kod, który wykona taką operację także dla zmiennych złożonych, czyli struktur zawierających odwołania do kolejnych struktur. Jedyne założenie, w które wolno uwierzyć: dana zmienna nie zawiera nigdzie w sobie odwołania do siebie samej (czyli nie występuje cykliczność, które to utrudnienie także można łatwo obejść).
Zadanie to egzaminuje wasze głowy ze znajomości złożonych struktur danych w sposób bardzo zdecydowany. Niemniej, jest też bardzo proste. Kopiowanie odbywać się musi na zasadzie wcześniejszego rozpoznania, czym jest dana zmienna. Jeżeli nie jest to referencja, zwracamy zwykłą kopię. Jeżeli jest to referencja - doskonale - mamy wtedy jej typ z operatora ref i zależnie od tego iterujemy albo po tablicy, albo po haszu, pracowicie kopiując wszystkie klucze. Ponieważ jednak każdy element takiej pod-struktury może być kolejną referencją, najbezpieczniej nie robić prostej kopii, ale zapamiętać to, co zwróci wywołanie rekurencyjne naszej funkcji do kopiowania. Gwarantuje to nam, że skopiowana zostanie cała struktura, aż do napotkania wartości, które nie będą referencjami. Oto zresztą kod, który jak to ktoś powiedział jest więcej wart niż tysiąc słów opisu:
sub deepcopy { my $var = shift; if(! ref $var){ # jeżeli to zwykła zmienna, zwracamy kopię my $copy = $var; return $copy; } elsif(ref $var eq 'HASH'){ # hasz? to iterujemy po kopiach elementów my $copy = {}; foreach(keys %$var){ $copy->{$_} = deepcopy($var->{$_}); } return $copy; } elsif(ref $var eq 'ARRAY'){ # tablica? żaden problem my $copy = []; foreach(@$var){ push @{$copy}, deepcopy($_); } return $copy; } elsif(ref $var eq 'SCALAR'){ # skalar? kopiujemy... my $copy = $$var; return \$copy; } else{ # reszty nie kopiujemy, żeby nie wpaść w paranoję :) warn 'Nie kopiuję GLOBA, KODU, obiektów i innych dziwnych rzeczy'; } return undef; }Tutaj należy jeszcze wyjaśnić, dlaczego nie zwracamy bezpośrednio wartości prostych zmiennych, tylko przez nadmiarowy wydawałoby się zapis:my $copy = $var; return $copy;Warto zrobić kopię dlatego, że samo $var może nie być tym, na co wygląda. Może to być np. zmienna związana, może to być alias innej zmiennej, może to być wreszcie zmienna lokalizowana, która po wyjściu z kontekstu zniknie lub zmieni się... zrobienie kopii przez przypisanie operatorem przypisania gwarantuje nam odrobinę mniej wrażeń związanych z różnymi sztuczkami, na jakie można się "nadziać". - (1p) Zadanie dowolne, dotyczące perla. Uwaga: powinno ono być dostatecznie przemyślane i na odpowiednim poziomie :)
Zadania dla grupy 3
Start: 2007-05-18 13:00, czas: 30 minut czasu delty.-
Zestaw A: zadania standardowe (kursowe)
- (1p) Wyjaśnij na czym polega działanie pseudoklasy SUPER.
Jest to nazwa określająca klasę bezpośrednio rodzicielską w hierarchii klas i wprowadzona została po to, aby ułatwić odwoływanie się do metod dziedziczonych bezpośrednio. Można za pomocą super dostać się nawet do klasy UNIVERSAL np. za pomocą takiego kodu:
perl -le '$a={};bless $a;print $a->SUPER::can("isa")'W takim kontekście otrzymujemy coś w rodzaju CODE(0x6205f0), czyli referencję do kodu... a to świadczy o tym, że kod taki istnieje i wobec użycia pseudoklasy SUPER w pakiecie main kod ten może pochodzić jedynie z pakietu UNIVERSAL. Zresztą łatwo to sprawdzić, wystarczy wypisać adres referencji do kodu metody isa z pakietu UNIVERSAL:perl -le 'print \&UNIVERSAL::isa'i gotowe. Porównanie tych dwóch adresów powinno dać w efekcie taki sam adres, ale może się zdarzyć, że zmieni się on pomiędzy kolejnymi uruchomieniami programu, dlatego obie instrukcje print warto umieścić w jednym programie. A w ogóle sam kod z bless można napisać krócej:perl -le 'print \&UNIVERSAL::isa; print +(bless {})->SUPER::can("isa");'W codziennej obiektowej praktyce odwołanie $self->SUPER::metoda jest identyczne z np. $self->KLASA::metoda, o ile KLASA jest bezpośrednim rodzicem w hierarchii dziedziczenia. - (2p) Zaproponuj sposób na ukazanie/wydobycie z kodu całej hierarchii dziedziczenia jaka jest tworzona w typowych hierarchiach klas. To znaczy, że mając egzemplarz danej klasy - możesz pokazać wszystkie (!) klasy, po których ona dziedziczy (włączając w to dziedziczenie wielokrotne).
Zadanie to można zrobić na przynajmniej dwa sposoby. Pierwszy z nich przydaje się gdy tworzymy własną hierarchię klas, drugi - nieco bardziej zaawansowany - jest pomocny wtedy gdy używamy obcej hierarchii klas i chcemy zobaczyć po czym dziedziczą. Oto pierwszy sposób: w każdej klasie tworzymy metodę np. printISA, która wypisuje po prostu to, co ustawiono w tym pakiecie w tej tablicy. Wywołanie tej metody powinno także wołać wszystkie metody dziedziczone i w ten sposób można zobaczyć po czym dziedziczą nasze klasy. Drugi sposób to użycie przestrzeni nazw UNIVERSAL i umieszczenie w niej funkcji wypisującej wszystkie tablice ISA jakie znalezione zostaną w klasie danego obiektu. Oto sposób:
package UNIVERSAL; sub printISA { no strict; my $class = shift; $class = ref $class || $class || return print "To nie obiekt!"; *isa = \@{$class."::ISA"}; print "klasa: $class: @isa\n"; printISA($_) for @isa; }Taki kod dla programu np. takiego:package A; sub new { bless {@_[1..$#_]},ref $_[0] || $_[0] || 'A'; } package B; our @ISA = qw(A); package C; our @ISA = qw(B); package D; our @ISA = qw(A C); package main; my $o = D->new(); $o->printISA();Wyświetli coś w postaci:klasa D: A C klasa A: klasa C: B klasa B: A klasa A:Ten drugi sposób nie jest wymagany przy odpowiedzi - całkowicie wystarczy pierwsze, proste rozwiązanie (nie zilustrowane tutaj żadnym większym przykładem). - (1p) Kiedy dochodzi w perlu do wywołania destruktora obiektu?
Oczywiście wtedy, gdy wewnętrzny licznik referencji do tego obiektu osiąga wartość zero. A to z kolei następuje wtedy, gdy do danego obiektu nie odwołuje się już żadna 'silna' referencja. Sytuacja taka zdarza się najczęściej wtedy, gdy obiekt jest niszczony przez operator przypisania lub wychodzi poza zakres swojej widoczoności leksykalnej:
$obj = undef; # jawna destrukcja obiektu (zniknie gdy nic na niego nie wskazuje POZA $obj) { my $obj; # deklaracja zmiennej lokalnej w bloku $obj = Obj->new(); # tworzenie nowego obiektu } # wyjście z bloku - utrata zasięgu zmiennej $obj # wyjście poza zakres - gdy zmienna $obj przestaje istniećDestruktor można także uruchomić własnoręcznie poprzez wywołanie metody DESTROY na instancji obiektu. - (1p) Czy klasa może dziedziczyć po sobie samej? Czyli, czy zadziała kod:
package Klasa; use base qw(Klasa); #... 1;Odpowiedź uzasadnij :)Kod pokazany wyżej nie zadziała, ale klasa MOŻE dziedziczyć po sobie samej, jeżeli do określenia zależności pomiędzy obiektami użyje się tablicy @ISA. Najlepiej rzucić okiem na kod:package BLA; $| = 1; our @ISA = qw(BLA); # dziedziczenie po sobie samym! sub new{ bless {} } sub bla { my $self = shift; my $text = shift; print $text; sleep 1; $self->SUPER::bla('#'); } package main; use strict; my $a = BLA->new(); $a->bla('dziala?');Taki kod efektownie działa a efekty jego działania widać w postaci mnóstwa tekstu wyświetlanego na ekranie. Pozostawienie programu na dłuższy czas kończy się komunikatem o zbyt głębokiej rekurencji (zauważ gdzie!). Co ciekawe, mamy tu idealny przypadek dziedziczenia po sobie samym, za pomocą mechanizmu SUPER. Inna sprawa, że nowszy rodzaj kodu, ten w którym używa się pragmy kompilatora powoduje że takie dziedziczenie już nie działa: jeżeli zastąpimy wiersz z:our @ISA = qw(BLA);wierszem:use base qw(BLA);to kod nie zadziała, ponieważ program zakończy się z błędem "Can't locate object method "bla" via package "BLA"...". Fajne! :) - (2p) Pytanie dowolne dotyczące obiektów w perlu. Uwaga: należy prawidłowo i jednoznacznie zadać sobie pytanie i poprawnie na nie odpowiedzieć. Nie wystarczy wyłącznie "zacytować" kodu (nie będę się domyślał ocb), i nie wystarczy zażądać czegoś w stylu "napisz konstruktor" (chyba że będzie to rzeczywiście coś ciekawego) :P Zestaw B: zadania powtórzeniowe (z całości):
- (2p) Napisz funkcję (być może wykorzystującą techniki callback udostępniane przez moduł File::Find), która przeskanuje twój katalog domowy i wyświetli ewentualne różnice w czasie utworzenia każdego pliku oraz czasie modyfikacji takiego pliku (jak oczywiście pamiętasz, istnieją w perlu operatory do takich testów, a każdy plik związany jest z trzema różnymi datami, które niekoniecznie muszą być różne).
Zadanie to jest bardzo proste, pod warunkiem, że przeczyta się dokumentację modułu File::Find lub po prostu chodzi na wykłady (to taka nic nie insynuująca dygresja) :) Zatem rozwiązanie jest proste i wygląda tak:
use File::Find; sub callback { my $ctime = -C $_; my $atime = -A $_; my $diff = $ctime - $atime; print "$diff\t$File::Find::name\n"; } find( \&callback, $ARGV[0] || '.');I już działa. Funkcja find będzie skanować katalog podany w drugim argumencie (domyślnie bieżący), i dla każdego pliku wywoła funkcję callback, która będzie wtedy widziała zmienną domyślną $_ w taki sposób, że będzie w niej nazwa akurat przetwarzanego pliku, a bieżącym katalogiem będzie katalog tego pliku. Dlatego można wykonać proste testy w stylu -C $_ w celu zdobycia czasu utworzenia pliku, itp. - (2p) Wyjaśnij na czym polega wycofywanie (podpowiedź: dotyczy to wyrażeń regularnych).
Wycofywanie jest to proces poszukiwania dopasowania w przypadku, gdy możliwych jest wiele sposób na dopasowanie, a dotychczas sprawdzone rozwiązania nie dały poprawnego wyniku. Ma ono miejsce najczęściej w przypadku kwantyfikatorów zachłannych lub leniwych - np.:
/.*bla$/zachłanny kwantyfikator * dopasuje wszystkie znaki aż do końca łańcucha a potem maszyna spróbuje dopasować literę b z wyrazu bla i ponieważ dopasowanie się nie uda, wypróbowane zostaną inne możliwości - * która pochłonie tylko część znaków (bez ostatniego) i tak dalej, aż do momentu, gdy * dopasowuje wszystkie poza ostatnimi trzema znakami w napisie. Wtedy dopasować się mogą litery bla i dopasowanie jest zakończone sukcesem. W przypadku gdy napis jest długi (ma setki znaków) takie dopasowanie będzie szybkie (tylko 3 wycofania). Alternatywna postać niezachłanna wycofa się więcej razy:/.*?bla$/gdy napis będzie długi, ponieważ dopasowane zostanie zero znaków i nastąpi próba dopasowania litery b, a gdy jej nie będzie - wycowanie z tego rozwiązania i dopasowanie jednego znaku i litery b, potem kolejne wycofanie itp. Nawet gdy uda się dopasować gdzieś w tekście wyraz bla (który występuje oczywście bardzo często :P), to nie powiedzie się próba dopasowania końca napisu $ i znowu nastąpi wycowanie i pochłonięcie jeszcze jednego znaku. Zatem - jak widać wycofywanie może być kosztowne i w różnych sytuacjach koszta dotyczyć będą różnych wersji kwantyfikatora. - (1p) W jaki sposób, bez użycia polecenia if, ustawić wartość zmiennej na 1, ale TYLKO wtedy, gdy ta zmienna nie była wcześniej ustawiona?
No, to zadanie jest tak proste, że ten kto nie odpowiedział, niech się wstydzi! Oczywiście chodzi o zapis z "or" danym jako operator ||:
$a = $a || 1;Działanie jest rzeczywiście takie, że zmienna $a uzyska wartość 1 TYLKO gdy jej poprzednia wartość była równoznaczna z false, czyli wynosiła 0, "" lub undef. - (1p) Czy lokalizowanie fragmentu zmiennej złożonej jest możliwe?
Tak, jest całkowicie możliwe i poprawne. Można zatem napisać:
@tab = (1,2,3); local $tab[1];i mamy zlokalizowaną zmienną, która dodatkowo przesłania prawdziwą wartość drugiego elementu tablicy @tab. - (1p) Zadanie dowolne, dotyczące perla. Uwaga: powinno ono być dostatecznie przemyślane i na odpowiednim poziomie :)
Zadania dla grupy 4
Start: 2007-05-18 14:30, czas: 30 minut czasu delty.-
Zestaw A: zadania standardowe (kursowe)
- (1p) Opisz zachowanie perla w przypadku wywołania nazwy funkcji, która nie została nigdzie zdefiniowana.
Standardowym zachowaniem jest sprawdzenie hierarchii klas, o ile określono dziedziczenie w tablicy @ISA, potem odbywa się poszukiwanie metody AUTOLOAD. W trakcie szukania sprawdzana jest również klasa UNIVERSAL.
- (2p) W jaki sposób można zdefiniować metody akcesorów i mutatorów klasy, nie pisząc ich explicite w kodzie? Zaproponuj przynajmniej jedną technikę :)
Należy wykorzystać procedurę AUTOLOAD, która będzie przechwytywać wywołania nieistniejących metod. Rozwiązanie to sprawdza się także w dziedziczeniu. Wewnątrz metody AUTOLOAD istnieć powinna zmienna pakietowa $AUTOLOAD, której wartość jest magicznie ustawiana na pełną, kwalifikowaną nazwę metody wywołanej. Można użyć tej informacji do określenia, co zrobić z obiektem (który jest przekazywany w pierwszym parametrze). Oto przykładowy kod metody AUTOLOAD, która pozwala ustawić dowolną wartość w obiekcie zbudowanym w oparciu o referencję do hasza. Nazwa pola pochodzi z nazwy metody wprost, a ustawienie/pobranie danych określone jest przez liczbę argumentów:
sub AUTOLOAD { our $AUTOLOAD; my $self = shift; if($AUTOLOAD =~ s/.*:://){ my $val = shift; if(defined $val){ # set $self->{$AUTOLOAD} = $val; } else{ return $self->{$AUTOLOAD}; } } }Zastosowanie może być np. takie:$obj->color(12); print $obj->color; - (1p) W jaki sposób napisać w perlu program, który wszystkie nieznane polecenia przekazuje do swojego środowiska uruchomieniowego? Np. rozważ jak napisać moduł BLA, aby działał taki kod:
use BLA; $a = "-l"; ls $a; pwd; cd;oraz zapewnij, że KAŻDA nieznana perlowi funkcja zostanie wykonana na poziomie systemu, który uruchamia samego perla :)Wystarczy skorzystać z metody AUTOLOAD. Każde użycie niezidentyfikowanej funkcji przechwycone przez nią powinno zostać przekazane do system razem z parametrami z @_. I to wszystko. :) - (1p) W jaki sposób uniknąć przeszukiwania hierarchii klas, które odbywa się w celu wywołania destruktora dziedziczonego w przypadku, gdy destruktor w danej klasie nie jest zdefiniowany?
Należy ten destruktor jawnie zdefiniować, nawet gdyby miał być pusty. Perl znajdzie go wtedy w klasie i nie będzie szukał w hierarchii. :)
- (2p) Pytanie dowolne dotyczące obiektów w perlu. Uwaga: należy prawidłowo i jednoznacznie zadać sobie pytanie i poprawnie na nie odpowiedzieć. Nie wystarczy wyłącznie "zacytować" kodu (nie będę się domyślał ocb), i nie wystarczy zażądać czegoś w stylu "napisz konstruktor" (chyba że będzie to rzeczywiście coś ciekawego) :P Zestaw B: zadania powtórzeniowe (z całości):
- (2p) Napisz program perlowy działający podobnie jak funkcja silnia, obliczający oczywiście silnię. Pamiętaj: nie chodzi o program, który oblicza silnię za pomocą funkcji - silnia. Zrób tak, aby twój program był czymś jak funkcja, a obliczenie przeprowadź w powłoce systemowej:
silnia.pl 10Oczywiście ten program powinien wywoływać sam siebie, a jednorazowo liczyć tylko jeden fragment silni. Wykorzystaj przekazywanie parametrów do programu, i wczytywanie wyników z programu.I znowu zadanie bardzo proste, oto kod programiku:#!/usr/bin/perl -w use strict; my $liczba = shift @ARGV || 1; print $liczba and exit if $liczba <=1; my $cmd = "perl $0 ".($liczba-1); my $res = `$cmd`; print $res * $liczba;Kod ten działa zupełnie jak typowa funkcja silnia, wywołując się rekurencyjnie, ale za pomocą systemu... zatem dla większych wartości silni będzie większa liczba jednocześnie działających procesów. Sposób ten działa :) - (2p) W jaki sposób realizuje się programowanie funkcjonalne w perlu? Podaj jakieś proste przykłady.
Pewne elementy programowania funkcjonalnego można zrealizować za pomocą domknięć, np.
sub generator_powitania { my $powitanie_poczatek = shift; return sub { print $powitanie_poczatek . " " . shift() . "\n"; } }Taki generatorek można wykorzystać do zrobienia funkcji, które będą pisały powitania:my $goscie = generator_powitania('witaj gosciu'); my $vipy = generator_powitania('uprzejmie witam'); # i potem: $goscie->(1); $goscie->(2); ... $vipy->('sir Long John'); $vipy->('mr Bean'); - (1p) Czy istnieje operator ?..? w perlu?
Tak, i jest przestarzały. Oznacza to samo co !~ / ... /.
- (1p) Czym się różni zasięg leksykalny zmiennej od zasięgu dynamicznego?
Zasięg dynamiczny jest ustawiany dla zmiennej lub stałej przez dyrektywę local i powoduje że dany obiekt przez nią modyfikowany staje się globalny w obrębie całego bloku, także we wszystkich użytych w tym bloku funkcjach. Zasięg leksykalny jest jakby przeciwieństwem zasięgu dynamicznego - zmienna widoczna jest tylko w obrębie bloku, w którym została zdefiniowana jako leksykalna. Różnic jest więcej, ale wystarczy podanie dowolnej i ta wydaje mi się najważniejsza. Inna różnica (również ważna) to to, że dyrektywa local NIE tworzy nowych zmiennych, natomiast my zawsze je tworzy. Itp.
- (1p) Zadanie dowolne, dotyczące perla. Uwaga: powinno ono być dostatecznie przemyślane i na odpowiednim poziomie :)
Jeżeli na tej stronie znalazłeś błąd, lub znasz lepsze wyjaśnienia zadań, proszę, napisz do mnie na adres manty.
Uniwersytet Gdański - Instytut Informatyki - Strona domowa - Perl - Kolokwia