Wyjściowka nr. 6 :L
Uniwersytet Gdański - Instytut Matematyki - Zakład Informatyki - Strona domowaPytania i zadania
Odpowiedz na zebrane poniżej zadania.
Odpowiedzi wyślij mailem pod tyt. [kolo 6] grupaN Imię Nazwisko (N-numer grupy)
Przestrzegaj limitu czasu pisania - max 20 minut.
Max punktów do zdobycia: 7. Powodzenia!
Zadania dla grupy 1
Start: 2007-04-18 15:10, czas: 20 minut czasu delty.- To zadanie składa się z części. Za wykonanie poprawnie każdej z nich można otrzymać dodatkowy punkt:
- (1p) Napisz kod nieobiektowego modułu Mod::AB w którym zaimplementowane będą funkcje A oraz B (wszystko jedno, co będą robić).
- (1p) Moduł powinien bezwarunkowo eksportować funkcję B do przestrzeni nazw pakietu wywołującego.
- (1p) Moduł powinien na żądanie eksportować funkcję A do przestrzeni nazw pakietu wywołującego.
Kod takiego modułu może być bardzo prosty, wystarczy leciutko zmodyfikować ogólny szablon typowego modułu:# plik AB.pm umieszczony w katalogu Mod package AB; use base qw(Exporter); our @EXPORT = qw(B); # export bezwarunkowy our @EXPORT_OK = qw(A); # export na żądanie sub B {} sub A {} 1; - (1p) Wyjaśnij, czym różni się use od require w kodzie dołączającym jakiś moduł (np. use Data::Dumper zamiast require Data::Dumper).
Podstawowa różnica pomiędzy use a require jest taka, że dyrektywa (lub też pragma) kompilatora use jest przetwarzana na etapie kompilacji programu, natomiast wykonanie require następuje dopiero podczas wykonywania programu, jest więc opóźnione. Aby zasymulować use za pomocą require należy skorzystać z bloków BEGIN, aby wymusić wykonanie na etapie kompilacji, i wtedy:
BEGIN{ require Moduł; Moduł->import; }przy czym pamiętać należy, że moduł musi być podany bez cudzysłowów jako goła nazwa (szukany wtedy będzie plik Moduł.pm). - (2p) Przeanalizuj program przedstawiony poniżej i określ, jaka jest wartość zmiennej $b po stu wykonaniach pętli for. Wykorzystaj do tego celu debugger perla. W odpowiedzi wystarczy napisać jakie polecenia trzeba podać debuggerowi.
#!/usr/bin/perl -wl use strict; my $i = 1; my $a = 0; my $b = 2; for($i=0; $i < 1000; $i++ ){ $a += $i - $b; $b += $i; $i += $b - $a; }Zadanie to jest bardzo proste i można wykonać je na kilka różnych sposobów (jeden z nich opiszę, a swoje własne próby i poprawki możecie mi podesłać). Po pierwsze należało do programu dodać za pętlą for dowolną instrukcję perla (gdyż w debuggerze łatwiej ustawić punkt przerwania programu za pętlą gdy jest na czym - łatwiej niż w ostatnim jej wierszu - w zamykającej klamrze). W naszym przypadku może to być np. print "$i, $a, $b\n"; ale dokładna treść tej instrukcji nie ma znaczenia, gdyż nie dojdzie do jej wykonania. Może to być nawet po prostu sam print. Kolejnym krokiem jest uruchomienie debuggera perla z naszym programem (zapisanym np. w pliku a.pl). Wszystko pokazuje rysunek poniżej:Program po uruchomieniu zatrzymany jest w linii 3. Wpisujemy polecenie l 1-999 aby wyświetlić cały kod programu (dla wygody). Widać po wykonaniu tego polecenia, że zatrzymanie nastąpiło w wierszu 3 (zaznaczone jest przez znaki ==>), oraz że nasza dodana linia z dodanym poleceniem print znajduje się w wierszu o numerze 12. Niemożność zatrzymania programu za pętlą była jednym z głównych problemów, z którymi sobie nie poradziliście :P. Teraz gdy wszystko widać, możemy zdefiniować kilka punktów przerwania. W zadaniu chodzi o określenie, jaka jest wartość zmiennej $b po stu wykonaniach pętli for. Zatem, trzeba zatrzymać program, gdy wartość zmiennej $i (licznika pętli) osiągnie wartość 100 - wtedy będzie można przeegzaminować pozostałe zmienne w programie, w tym zmienną $b. Ustawiamy zatem: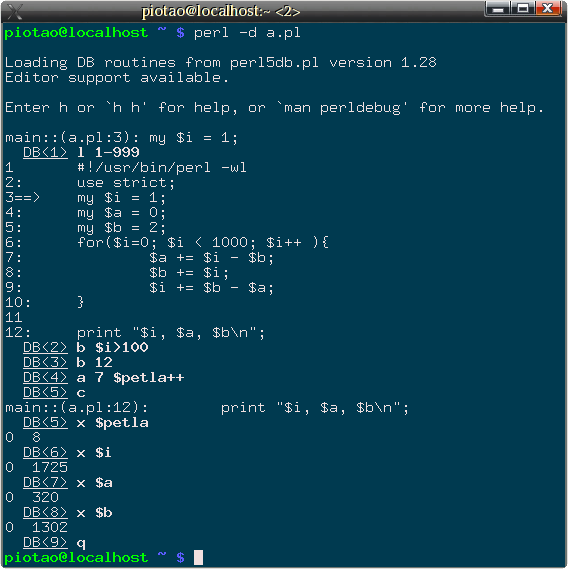
Rys. 1: Przebieg sesji debugowania skryptu.b $i=100Program zatrzyma się wtedy, gdy debugger zauważy, że wartość zmiennej $i przekroczy 100, więc mamy zapewnione, że znajdziemy się w odpowiednim miejscu i czasie, aby podejrzeć zmienną $b. Uruchomienie takiego programu następuje po poleceniu c (continue) - i niestety program się kończy, ponieważ... nie dochodzi do wykonania stu iteracji pętli! Osoby, które napisały mi taką odpowiedź miały zaliczone to zadanie. Niemniej można program prześledzić i wykryć, ile jest tych iteracji, które się w ogóle wykonują. W tym celu - w naszym debuggerze ustawiamy wszystko jak poprzednio, ale dodajemy dodatkowe polecenia:b 12Zatrzymanie programu w wierszu 12-stym, tuż przed dodaną przez nas instrukcją print, oraz:a 7 $petla++które to polecenie WYKONA w wierszu 7 programu dodatkową akcję: zinkrementuje zmienną $petla. Zmienna ta nie istnieje w programie, ale zostanie utworzona przez debuggera tak jakby było w wierszu 7 wpisane, co podaliśmy. Dzięki temu mamy faktycznie dodany do programu licznik wykonanych pętli. Gdy teraz uruchomimy program poleceniem c, to jego wykonanie przebiegać będzie tak samo jak poprzednio, z tym, że teraz będzie jeszcze inkrementowana zmienna $petla, a pierwszy punkt przerwania (dla $i>100) nie zostanie osiągnięty (jak poprzednio), za to zatrzymamy się na drugim ustawionym punkcie przerwania jakim jest polecenie stopu bezwarunkowego (b 12 - nie mylić z witaminą B12!). Po zatrzymaniu się przed wykonaniem wiersza 12 sprawdzamy ręcznie wartość zmiennej $petla i widzimy, że wynosi ona 8, zatem pętla for zdołała wykonać tylko 8 iteracji! Pozostałe zmienne łatwo wyświetlić i odpowiedź na zadanie jest wtedy oczywista. - (1p) Zadanie dowolne.
Zadania dla grupy 2
Start: 2007-04-19 16:18, czas: 20 minut czasu delty.Uwaga. Dla wszystkich osób z grupy 2 dodałem dwa dodatkowe, bonusowe zadania, w ramach rekompensaty za zbyt trudne zadanie 8 z poprzedniego kolokwium, które z mojej winy przekraczało trochę wymagany poziom. Czas kolokwium przedłużam o 7 minut, a jednocześnie macie możliwość zdobycia dwóch punktów ponad limit. Powodzenia!
- (2p) Do czego służy moduł Exporter? Wyjaśnij przynajmniej jedno z jego zastosowań i podeprzyj je stosownym przykładem.
Moduł ten służy do importu symboli z modułów do aktualnie uzywanego pakietu. Typowym zastosowaniem jest import nazw do przestrzeni main, np.:
use Test::Wrap qw(wrap); # symbol wrap zostal zaimportowany do bieżącego pakietu # i można używać go pisząc po prostu: wrap '','','tekst'; # zamiast: Text::Wrap::wrap '','','tekst2'; - (1p) Czy pakiet Store::File oraz Store::File::Csv mogą znajdować się w różnych miejscach w systemie plików, tak jakby nie miały ze sobą żadnego związku? Niezależnie od odpowiedzi, uzasadnij ją :)
Oczywiście że mogą, ponieważ symbol :: pomiędzy członami w nazwach nie określa żadnej zależności pomiędzy pakietami. Dlatego moduł Store::File może znajdować się w standardowej dystrybucji perla, natomiast moduł Store::File::Csv w katalogach stworzonych przez użytkownika w zupełnie innym miejscu. Wymagane jest w każdym przypadku, aby pełna ścieżka do katalogów Store (niezależnie od ich rzeczywistego położenia) znajdowała się w tablicy @INC, którą można modyfikować zewnętrznie za pomocą zmiennej środowiskowej PERL5LIB lub wewnętrznie za pomocą pragmy use lib qw(scieżka1 scieżka2 itp);.
- (1p) Zapewne wiesz że na końcu prawidłowo napisanego pakietu należy umieścić wyrażenie, które ewaluowane jest jako prawda lub fałsz (dlatego tradycyjnie umieszcza się tam cyfrę 1). Czy jeżeli w jednym pliku znajduje się kilka pakietów, to także należy pamiętać o tej regule?
Nie trzeba o tym pamiętać. Jeżeli następuje zmiana pakietu za pomocą dyrektywy package i odbywa się w obrębie jednego pliku, to pakiet jest już załadowany i nie ma sensu tego potwierdzać wstawianiem kodu oznaczającego 'prawdę' na jego końcu:
# plik jaks_program.pl package bla1; #tu nie trzeba package bla2; #tu tez nie package bla3; #tu tez nie package main; #program glownyReguła ta jednak musi być zachowana, gdy ostatnim pakietem w pliku jest pakiet ładowany, to znaczy jeżeli plik nazywa się Bla.pm to:# plik Bla.pm package bla1; ... package bla2; ... package Bla; ... 1;Oczywiście zachowanie tradycyjnego wpisu 1; na końcu każdego pakietu zwykle niczemu nie przeszkadza. - (2p) Przeanalizuj program przedstawiony poniżej i określ, w którym miejscu znajduje się błąd. Wykorzystaj debugger perla a w odpowiedzi przedstaw polecenia, które w nim wykorzystałeś.
#!/usr/bin/perl -wl use strict; my %DANE = ( 2 => qw(liczba podzielna przez 2), 3 => qw(liczba podzielna przez 3), 4 => qw(liczba podzielna przez 4), 5 => qw(liczba podzielna przez 5), ); my $cycle = 0; do{ print $DANE{2} if $cycle % 2; print $DANE{3} if $cycle % 3; print $DANE{4} if $cycle % 4; print $DANE{5} if $cycle % 5; $cycle++; } until $cycle >= 100;Kompilacja programu na sposób perl -wc a.pl (program jest w pliku a.pl), wskazuje, że składnia jest w porządku (syntax OK). Uruchomienie powoduje, że na ekranie pojawiają się liczby, ale także wiele ostrzeżeń o niezdefiniowanej wartości w poleceniu print. W takiej sytuacji, co bardziej doświadczeni programiści od razu podejrzewali struktury danych i zmienne. Ten rodzaj ostrzeżenia pojawia się zwykle tam, gdzie instrukcja print otrzymuje do wypisania wartość niezdefiniowaną. Wartość taka wskazuje zwykle (przy odpowiednim stylu pisania kodu) sytuację wymagającą uwagi. Zachęcam do przestrzegania zasady, że wartość undef jako taka NIE przenosi ze sobą żadnej informacji, to znaczy - nie akceptuje jej jako nośnika danych w swoich programach. Wtedy wystąpienie undef będzie sygnałem błędu i może pomóc w analizie bardziej skomplikowanych programów. W każdym razie, uruchomienie tego programu w debuggerze perla zatrzymuje go na wierszu w którym definiowana jest zmienna %DANE. Wystarczy wykonać polecenie n (next) i przeanalizować co znajduje się wewnątrz tej zmiennej (za pomocą polecenia x \%DANE). Zobacz rysunek:Jak widać na załączonym obrazku, wartości hasza %DANE nie są takie, jak zapisano podczas ich definicji. Winę ponosi operator cytowania użyty do definiowania struktury: qw(...). Tworzy on listę słów i wstawia taką listę wprost w miejsce swojego wywołania, dlatego dostajemy coś w stylu: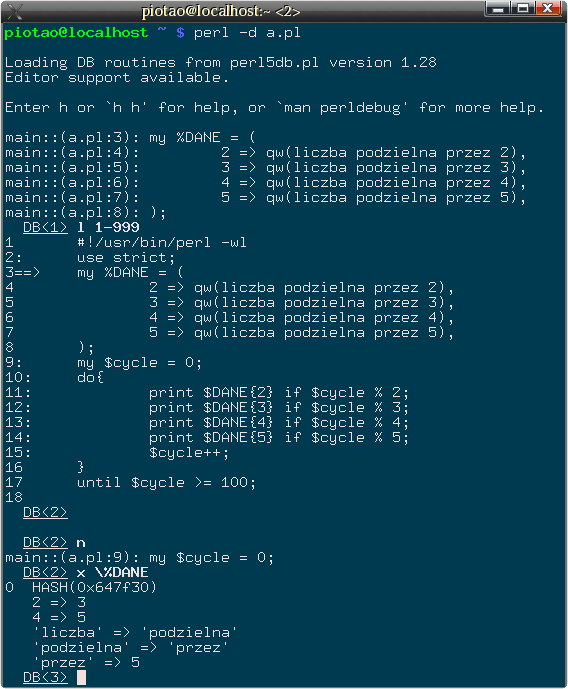
Rys. 2: Przebieg sesji debugowania programu.%DANE = (2,'liczba','podzielna','przez','2', 3, 'liczba', 'podzielna',.... );a to w prostej linii prowadzi do kodu rozumianego przez perla tak:%DANE = ( 2=>'liczba', podzielna=>'przez', 2=>3, liczba=>'podzielna',...);Błąd istnieje zatem w zapisie, a kompilator tego nie widzi, ponieważ hasz standardowo tworzy się z listy. Rzecz w tym, CO jest elementem listy, a co nie - ale tego kompilator już wiedzieć nie może :) Poprawienie tego kodu jest proste, wystarczy zamienić operator cytowania słów qw(...) na operator cytowania napisów q(...). - (bonus +1p)* Jak zdefiniować pakiet prywatny, którego nie można osobno załadować, widoczny tylko dla jednego, innego pakietu ładowanego jako moduł?
Wystarczy w pliku jakiegoś modułu, oprócz niego zdefiniować dodatkowy moduł o innej nazwie:
# plik bla.pm package fifka; ... package bla; ... 1;Modułem głównym, ładowanym przez perla jest moduł bla. Dodatkowo, moduł ten ma dostęp do modułu fifka wpisanego inline w tym samym pliku. Załadowanie modułu fifka za pomocą use fifka; jest niemożliwe, ponieważ nie istnieje nigdzie plik fifka.pm. Nie jest to w ścisłym tego znaczeniu pakiet prywatny, ale nie można go normalnie załadować i dystrybuowany musi być zawsze razem z modułem bla. - (bonus +1p) Jak za pomocą wyrażenia regularnego z pełnej ścieżki do pliku w systemie DOS uzyskać wszystkie składowe, to znaczy dysk, ścieżkę bez końcowego \, nazwę pliku i jego rozszerzenie bez kropki? Dla przykładowej ścieżki w postaci c:\windoze\system\temp\virus.swp wyrażenie musi pozwolić na uzyskanie fragmentów c:, \windoze\system\temp, virus oraz swp. Przyjmij, że ścieżka może nie zawierać oznaczenia dysku, plik może nie mieć rozszerzenia, a ścieżka może nie być podana...
Zadanie to jest zadaniem powtórzeniowym z wyrażeń regularnych, i ma rozwiązanie np. podobne do:
/(\w:)?((?:\\?\w*)+\\)?(\w+)(\.\w+)?$/Kolory w odpowiednich częściach wyrażenia mają na celu ułatwić orientację co do czego się dopasowuje. Działanie tego wyrażenia przedstawia poniższa tabelka (brak wartości zaznaczono myślnikiem!):Napis Dysk Ścieżka Plik Rozszerzenie c:\windoze\system\temp\virus.swp c: \windoze\system\temp\ virus .swp windoze\system\temp\virus.swp - windoze\system\temp\ virus .swp \windoze\system\temp\virus.swp - \windoze\system\temp\ virus .swp \virus.swp - \ virus .swp virus.swp - - virus .swp virus - - virus - c:wirus.swp c: - virus .swp c:virus c: - virus - c:\windoze\virus c: \windoze\ virus - - (1p) Zadanie dowolne.
Zadania dla grupy 3
Start: 2007-04-20 13:10, czas: 20 minut czasu delty.- (1p) W jaki sposób można wywołać funkcję myFunc z pakietu Funkcje, jeżeli napisany on został bez użycia pakietu Exporter?
Bardzo prosto: wystarczy napisać Funkcje::myFunc(); po uprzednim załadowaniu modułu Funkcje za pomocą use.
- (2p) W jaki sposób poprawić moduł Funky zawierający funkcje f1, f2 i f3 tak, aby było możliwe zaimportowanie ich przez use Funky qw(:all);?
Trzeba do modułu Funky na jego początku dopisać kod:
use base qw(Exporter); our %EXPORT_TAGS = ( all => [qw(f1 f2 f3)] ); - (2p) Za pomocą debuggera perlowego znajdź przynajmniej jeden błąd w programie przedstawionym poniżej i podaj polecenia, których użyłeś. Wyjaśnij też na czym polega błąd.
#!/usr/bin/perl -wl my $u = 11; sub A { my $a = 2; $u += $a; print "A: $u"; &B; } sub B { my $a = shift; $u -= $a+1; print "B: $u"; &A if $u > 0; } A(1);Po uważnej analizie widać już na drugi rzut oka gdzie jest błąd, i można obejść się bez debuggera, ale OK :) Oto log z sesji debuggera, uważni czytelnicy na pewno od razu zrozumieją o co chodzi:piotao@localhost ~ $ perl -d a.pl Loading DB routines from perl5db.pl version 1.28 Editor support available. Enter h or `h h' for help, or `man perldebug' for more help. main::(a.pl:2): my $u = 11; main::(a.pl:3): sub A { DB<1> l 1-99 1 #!/usr/bin/perl -wl 2==> my $u = 11; 3 sub A { 4: my $a = 2; 5: $u += $a; 6: print "A: $u"; 7: &B; 8 } 9 10 sub B { 11: my $a = shift; 12: $u -= $a+1; 13: print "B: $u"; 14: &A if $u > 0; 15 } 16 17: A(1); 18 DB<2> n main::(a.pl:17): A(1); DB<2> s main::A(a.pl:4): my $a = 2; DB<2> n main::A(a.pl:5): $u += $a; DB<2> main::A(a.pl:6): print "A: $u"; DB<2> A: 13 main::A(a.pl:7): &B; DB<2> s main::B(a.pl:11): my $a = shift; DB<2> n main::B(a.pl:12): $u -= $a+1; DB<2> main::B(a.pl:13): print "B: $u"; DB<2> B: 11 main::B(a.pl:14): &A if $u > 0; DB<2> s main::A(a.pl:4): my $a = 2; DB<2> n main::A(a.pl:5): $u += $a; DB<2> main::A(a.pl:6): print "A: $u"; DB<2> A: 13 main::A(a.pl:7): &B; DB<2> x \@_ 0 ARRAY(0x7db090) empty array DB<3> s main::B(a.pl:11): my $a = shift; DB<3> p @_ DB<4> x @_ empty array DB<5> n main::B(a.pl:12): $u -= $a+1; DB<5> x $a 0 undef DB<6> n Use of uninitialized value in addition (+) at a.pl line 12. at a.pl line 12 main::B called at a.pl line 7 main::A called at a.pl line 14 main::B called at a.pl line 7 main::A('undef') called at a.pl line 17 main::B(a.pl:13): print "B: $u"; DB<6> T . = main::B called from file `a.pl' line 7 . = main::A called from file `a.pl' line 14 . = main::B called from file `a.pl' line 7 . = main::A(undef) called from file `a.pl' line 17 DB<6> _Podsumowując, chodzi o to, że w programie działa rekurencja, w wyniku której dość nieostrożnie przekazywane są parametry. Oto, z procedury A, wołana jest procedura B w taki sposób, że wszystkie parametry A są do niej przekazane (dzięki notacji bez nawiasów i ze znakiem &). Wewnątrz B wszystkie otrzymane argumenty są widziane jako tablica @_, i z niej odbierany jest jeden z nich za pomocą shift. Powoduje to skrócenie tablicy @_ i kolejne wywołanie procedury A na tym poziomie przekazuje do niej już pustą listę argumentów. Procedura A wykonuje się i wywołuje &B, przekazując jej już zawsze pustą listę argumentów. A wewnątrz kodu B jest odbierany argument przez shift, który w tym momencie uzyskuje wartość undef i to właśnie powoduje liczne ostrzeżenia podczas normalnego uruchomienia programu. Widać to zresztą w logu z sesji debugowania. Przyczyną błędu jest niewłaściwie zbudowany program, w którym dochodzi do straty przekazywanych parametrów z wywołania na wywołanie. Wszystko przez zbyt standardowe użycie shift, które - bądź do bądź - zaleca się stosować! - (1p) Napisz program, który pobiera nazwę modułu z wiersza poleceń programu a następnie ładuje ten moduł. Na przykład: program.pl Time::HiRes - załaduje moduł Time::HiRes.
Zadanie to jest troszkę podstępne, gdyż modułu załadować w trakcie wykonania programu nie można przez use (bez użycia eval, o którym nie mówiliśmy i o który nie chodziło), natomiast require nie znajdzie pliku .pm na podstawie nazwy samego modułu. Zatem podaną nazwę należy nieco zmodyfikować, aby program mógł wykorzystywać "opóźnione" ładowanie modułu:
# program ładujący moduł o nazwie podanej w @ARGV use strict; use utf8; # pozwala na pl znaki w zmiennych my $moduł = shift @ARGV; $moduł =~ s/::/\//g; # zamiana :: na ukośniki ścieżek, Time::HiRes zmienia na Time/HiRes $moduł .= '.pm'; require $moduł; # dla sprawdzenia, czy np. Time::HiRes działa: if( $moduł =~ /HiRes/ ){ print Time::HiRes::time(); }Przykładowe uruchomienie programu przedstawione jest na rysunku 3: Rys. 4: Opóźnione ładowanie modułu Time::HiRes uzyskane za pomocą require.
Rys. 4: Opóźnione ładowanie modułu Time::HiRes uzyskane za pomocą require.
- (1p) Zadanie dowolne z modułów, pakietów i debuggera.
Zadania dla grupy 4
Start: 2007-04-20 14:40, czas: 20 minut czasu delty.- (1p) Czy jest jakiś sposób, aby z pakietu X::Y i funkcji xy tam zdefiniowanej wywołać funkcję x zdefiniowaną w pakiecie X?
Oczywiście, wystarczy w tym celu napisać wewnątrz funkcji xy:
sub xy { ... use X; X::x(...); ... }i to wystarczy. Pragma use ma zasięg ograniczony do obejmującego bloku, dlatego można używać jej do ładowania modułów widocznych w obrębie np. jednej funkcji. Nie jest to jednak zalecane, gdyż w preambule modułu nie widać, co zostaje w trakcie wykonania ładowane (problem bardziej akademicki, gdyż i tak moduł ładowany będzie w trakcie kompilacji już, ale utrudnione jest utrzymanie takiego kodu). - (1p) W module A zdefiniowano funkcję a, która wywołuje funckję b, zdefiniowaną w module B, która wywołuje funkcję a z modułu A. Czy w perlu możliwe jest zaprogramowanie takiej krzyżowej rekurencji? Co z dołączeniem odpowiednich modułów?
Da się tak zrobić, aby moduły krzyżowo ładowały swoje funkcje. Wykorzystano poniżej moduły o nazwach A.pm oraz C.pm (w celu uniknięcia konfliktu nazw z B::, które jest zdefiniowane w perlu). W obu modułach odbywa się eksportowanie nazwy odpowiedniej procedury, i dzięki temu są one dla siebie jednocześnie widoczne, chociaż moduły wywołują się krzyżowo:
# kod modułu A.pm package A; use base 'Exporter'; our @EXPORT = 'A'; use C; sub A { print "A\n"; C::C(); } 1;# kod modułu C.pm package C; use base Exporter; our @EXPORT = 'C'; use A; sub C { print "C\n"; A::A(); } 1;Takie moduły można wywołać w programie, pisząc chociażby:perl -e 'use A; A::A();'I to wystarczy, aby zobaczyć szereg przeplatających się liter A i C. :) - (1p) Którą funkcję wykona perl, jeżeli w programie zdefiniujesz swoją wersję sort, pisząc sub sort{...} a potem wywołasz ją pisząc np. sort 1,2,3;? Dlaczego nie ma konfliktu?
Nie ma konfliktu standardowego sort z własną funkcją sort dlatego, że obie te funkcje istnieją w odrębnych pakietach. Napisanie swojej własnej funkcji sort nie powoduje jeszcze 'nadpisania' lub zasłonięcia systemowej wersji. Aby to zrobić, należy skorzystać z modyfikacji tablicy symboli (a to nie jest temat na to koło). Perl wywoła swoją wersję sort, a żeby zmusić go do wykonania naszej wersji, należy poprzedzić ją w pełni kwalifikowaną nazwą, czyli dodać jeszcze do nazwy funkcji nazwę pakietu (powstanie np. main::sort jeżeli funkcję napisano w pakiecie main). Standarowy sort perla znajduje się w pseudopakiecie CORE i można wywoływać go jako CORE::sort, podobnie jak inne funkcje wbudowane perla.
- (3p) Za pomocą debuggera perlowego znajdź przynajmniej jeden błąd w programie przedstawionym poniżej i podaj polecenia, których użyłeś. Wyjaśnij też na czym polega błąd (lub błędy!). Wskazówka: program możesz zmienić, aby lepiej wykorzystać debugger.
#!/usr/bin/perl -w use strict; sub silnia { return 1 if $_=shift() < 2; return (+$_) * silnia($_-1); } print silnia(5);Ten program to majstersztyk jeżeli chodzi o kod, który się kompiluje, niewinnie wygląda, a NIE DZIAŁA. Krótki debug w debuggerze perlowym wykazuje jednak co się dzieje źle. Oto, po uruchomieniu, debugger znajduje się od razu w wierszu 5, gdzie następuje wywołanie print silnia(5);. Zatem log z poleceń wpisanych do debuggera powinien wyglądać np. tak:perl -d a.pl Loading DB routines from perl5db.pl version 1.28 Editor support available. Enter h or `h h' for help, or `man perldebug' for more help. main::(a.pl:7): print silnia(5); DB<1> v 4: return 1 if $_=shift() < 2; 5: return (+$_) * silnia($_-1); 6 } 7==> print silnia(5); 8 DB<1> s main::silnia(a.pl:4): return 1 if $_=shift() < 2; DB<1> x @_ 0 5 DB<2> n main::silnia(a.pl:5): return (+$_) * silnia($_-1); DB<2> x @_ empty array DB<3> x $_ 0 '' DB<4>Od razu widać, że nie zadziałało normalnie polecenie shift(). Co prawda wartość pierwszego elementu tablicy argumentów @_ przekazanych do procedury została pobrana i zdjęcia z @_, ale NIE została ona przypisana do zmiennej domyślnej $_ i to jest podstawowym źródłem błędu w tym kodzie. Oczywiście dalsze operacje bazują na $_ i nie mogą się powieść, ponieważ zmienna ta nie zawiera liczby. Dlatego działanie funkcji kończy się bardzo szybko, przedwcześnie. Błąd tkwi w wyrażeniu if $_ = shift () < 2;. - (1p) Zadanie dowolne.
Jeżeli na tej stronie znalazłeś błąd, lub znasz lepsze wyjaśnienia zadań, proszę, napisz do mnie na adres manty.
Uniwersytet Gdański - Instytut Informatyki - Strona domowa - Perl - Kolokwia[c] Piotr Arłukowicz, materiały z tej strony udostępnione są na licencji GNU.